
Deep learning gets thrown around in every SaaS product announcement, investor pitch, and vendor feature page. The term appears next to chatbots, fraud detection, image generation, and recommendation engines as though they are all the same technology doing the same thing. They are not. Deep learning is a specific subset of machine learning that uses multilayered neural networks to learn patterns from data, and it powers a growing share of the AI tools SaaS buyers now evaluate every quarter. But here is the question most explainers skip: does your business actually need deep learning, or is a simpler, cheaper approach the better call?
This guide explains what deep learning is, how it works under the hood, which architectures matter, where SaaS products use it today, what it costs to run, and when you should avoid it entirely.
Quick answer: Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to learn representations from complex data such as text, images, audio, and video. It powers capabilities like chatbots, image recognition, speech transcription, and generative AI. Deep learning differs from traditional machine learning primarily in its ability to learn features automatically from raw data, but it requires more compute, more data, and more monitoring to run reliably.
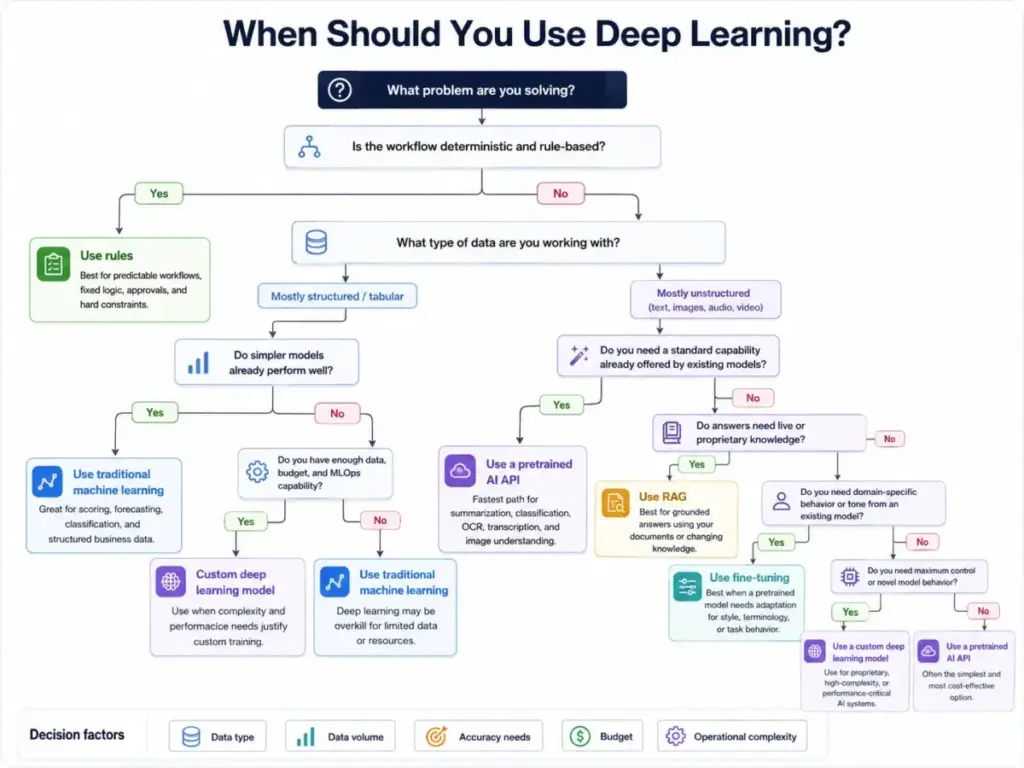
Do You Actually Need Deep Learning?
Before reading another paragraph about neural network architectures, answer these five questions honestly. They will save you months of evaluation time if the answer turns out to be “no.”
Use deep learning when:
- Your problem involves unstructured data: text, images, audio, video, or sensor streams
- Manual feature engineering has failed or is too expensive to maintain
- You need pattern recognition at a scale where rules and simple models break down
- You are building or buying generative AI features (chatbots, content generation, code assistants)
- You have enough labeled, high-quality training data to support model learning
- Your team can monitor, retrain, and govern a model in production
Postpone or skip deep learning when:
- Your dataset is small, structured, and tabular (a gradient-boosted tree may outperform a neural network)
- The workflow is rules-based and fully deterministic
- You need every output to be fully explainable for regulatory or legal reasons
- Compute and infrastructure budgets are strict
- Your team lacks the ability to monitor model drift and retrain after launch
- A pretrained API or vendor AI feature already solves the problem at lower cost
The honest answer for many SaaS buyers is that they do not need to build deep learning. They need to evaluate whether the vendor’s deep learning features work reliably, cost what they expect, and are governed properly. That evaluation requires understanding the concept, not training a model from scratch.
Deep Learning Explained in Plain English
The simple version
Deep learning teaches computers to recognize patterns in complex data by processing it through layers of artificial neurons. Each layer learns to detect progressively higher-level features. The first layer might detect edges in an image. The next detects shapes. A deeper layer recognizes an entire face. The key difference from traditional machine learning: deep learning figures out which features matter on its own instead of requiring a human to specify them manually.
The technical version
A deep learning model is a mathematical function composed of multiple layers of interconnected nodes (artificial neurons). Inputs are converted into numerical tensors, passed through layers where each neuron applies a weighted sum and an activation function, and compared against desired outputs using a loss function. During training, backpropagation sends error signals backward through the network, and gradient descent adjusts the weights to reduce future error. Early layers learn low-level patterns (edges, tokens, sound fragments), while deeper layers combine those patterns into higher-level representations. After training, the model performs inference by applying learned weights to new inputs.
The business version
For SaaS buyers, deep learning is the engine behind many product capabilities that have become table stakes: AI chatbots, copilots, speech transcription, computer vision, fraud detection, recommendation engines, semantic search, document extraction, and generative AI. Stanford HAI reports that U.S. private AI investment reached $285.9 billion in 2025, and generative AI hit 53% population adoption within three years. McKinsey estimates generative AI could add $2.6 trillion to $4.4 trillion annually across 63 use cases. The practical question is no longer whether deep learning exists. It is whether the vendor can make it reliable, governable, and cost-effective in production.
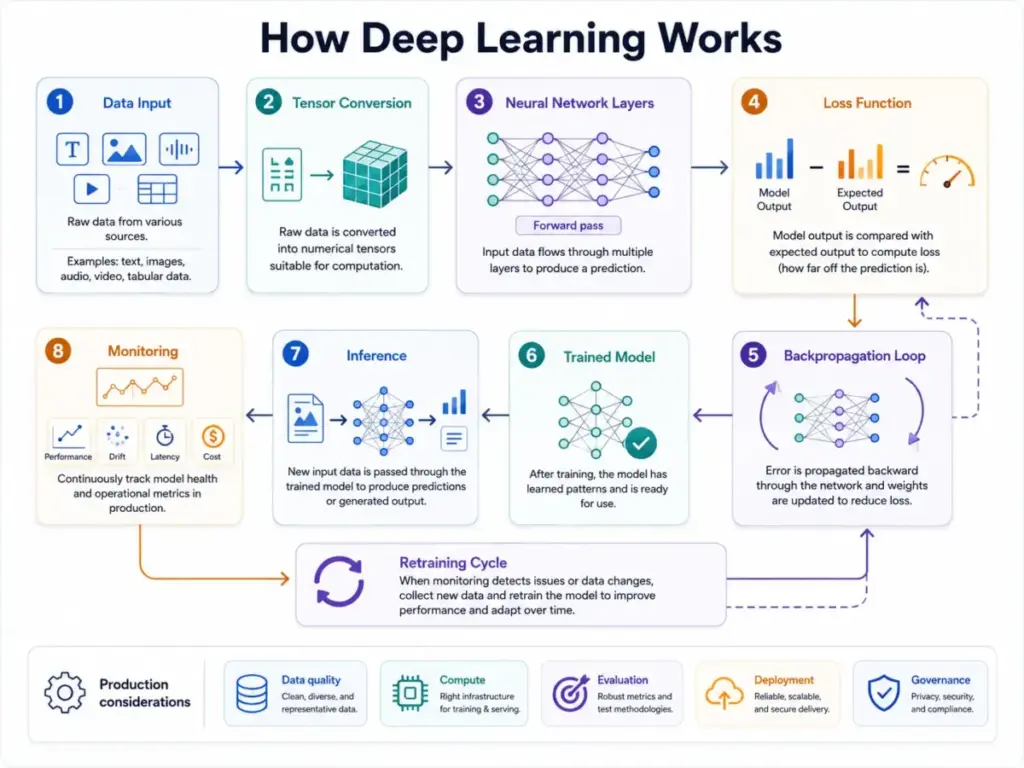
How Deep Learning Works
A deep learning workflow has two phases: training and inference. Understanding both matters because SaaS costs, latency, and governance requirements differ between them.
Training phase
- Data collection and preparation. Raw data (text, images, audio, structured records) is collected, cleaned, labeled if needed, and converted into numerical tensors. Data quality determines model quality. Poor labels, biased samples, or insufficient volume will produce unreliable outputs regardless of architecture.
- Forward pass. Input tensors flow through the network’s layers. Each neuron applies a weighted sum to its inputs, adds a bias term, and passes the result through an activation function. The output of one layer becomes the input to the next.
- Loss calculation. The network’s output is compared against the expected result using a loss function. The gap between predicted and actual output is quantified as a number.
- Backpropagation. The error signal propagates backward through the network. Each neuron learns how much it contributed to the overall error.
- Weight adjustment. Gradient descent (or a variant like Adam) adjusts the weights and biases to reduce the loss. This cycle repeats across thousands or millions of examples until the model converges.
- Evaluation. The trained model is tested against holdout data it has never seen. Metrics like accuracy, precision, recall, F1 score, or mean absolute error determine whether performance is acceptable.
Inference phase
After training, the model applies its learned weights to new inputs and produces predictions or generated outputs. In SaaS production, inference also requires data pipelines, model deployment infrastructure, monitoring for accuracy and drift, security controls, cost tracking, and human review for high-risk use cases.
Where things go wrong: Most deep learning failures happen outside the model itself. Data pipelines break. Labels are inconsistent. Monitoring is absent. Drift goes undetected for weeks. The model performs well in a notebook and poorly in production. I see this pattern repeatedly in buyer reviews on platforms like G2, where teams report steep learning curves and complex initial setup for data science and ML platforms.
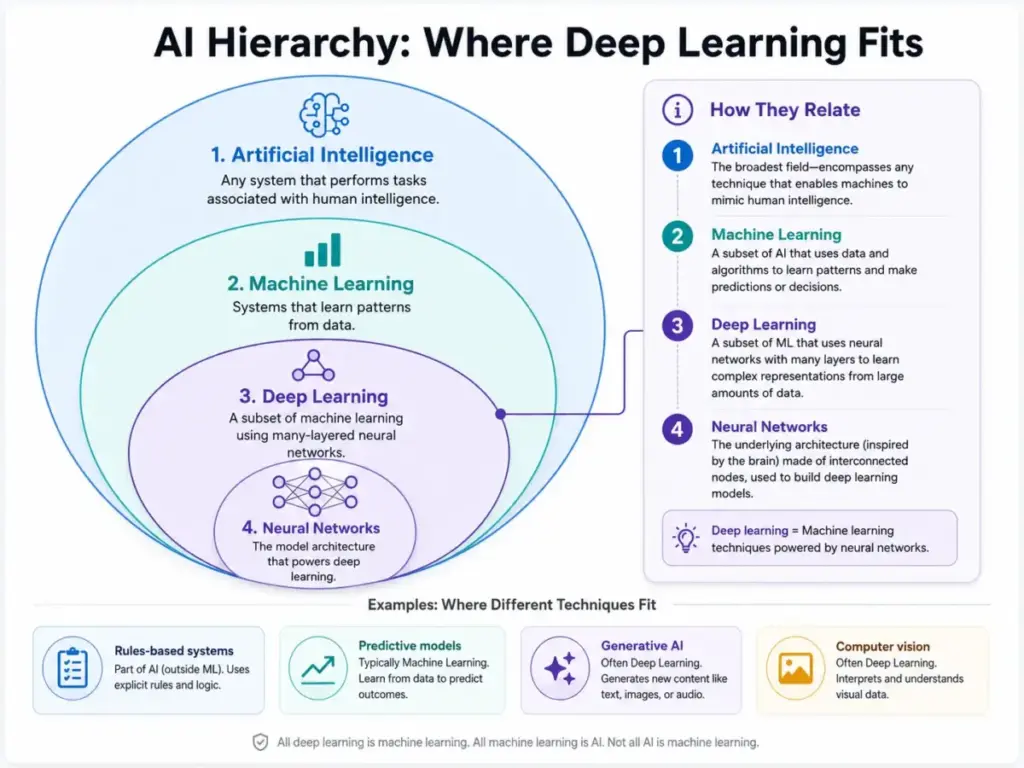
Deep Learning vs Machine Learning vs AI vs Neural Networks
One of the most common sources of confusion in SaaS buying is treating these terms as interchangeable. They are not. Here is how they relate.
| Concept | What it is | Relationship to deep learning | When a SaaS buyer encounters it |
|---|---|---|---|
| Artificial intelligence | The broadest category: any system that performs tasks typically requiring human intelligence | Deep learning is one method used to build AI systems. Not all AI uses deep learning. | Vendor says “AI-powered” on every feature page |
| Machine learning | A subset of AI where systems learn from data rather than following explicit rules | Deep learning is a subset of machine learning that uses multilayered neural networks | Vendor offers “ML-based predictions” or “intelligent automation” |
| Deep learning | A subset of ML using multilayered neural networks to learn representations from complex data | This is what we are explaining | Vendor uses transformers, CNNs, or foundation models behind a feature |
| Neural networks | The computational architecture deep learning models use | Neural networks are the building blocks; deep learning is the approach that uses them at depth | Vendor mentions “neural network” in technical docs |
| Large language models | A specific type of deep learning model trained on massive text data | LLMs are one application of deep learning (transformer architecture) | ChatGPT, Claude, Gemini, and enterprise copilots |
| Generative AI | AI that creates new content (text, images, audio, code) | Most generative AI systems use deep learning architectures | Image generators, chatbots, code assistants |
| RAG (Retrieval-Augmented Generation) | A pattern that combines retrieval with generation to ground LLM outputs | RAG is an application pattern built on top of deep learning models | Enterprise chatbots that reference internal documents |
What this means for buyers: When a vendor says “AI-powered,” ask which layer they mean. A rules-based automation that triggers emails is AI, but it is not deep learning. A chatbot that generates natural language responses using a transformer model is deep learning. The distinction matters because it determines data requirements, cost structure, explainability, and governance needs.
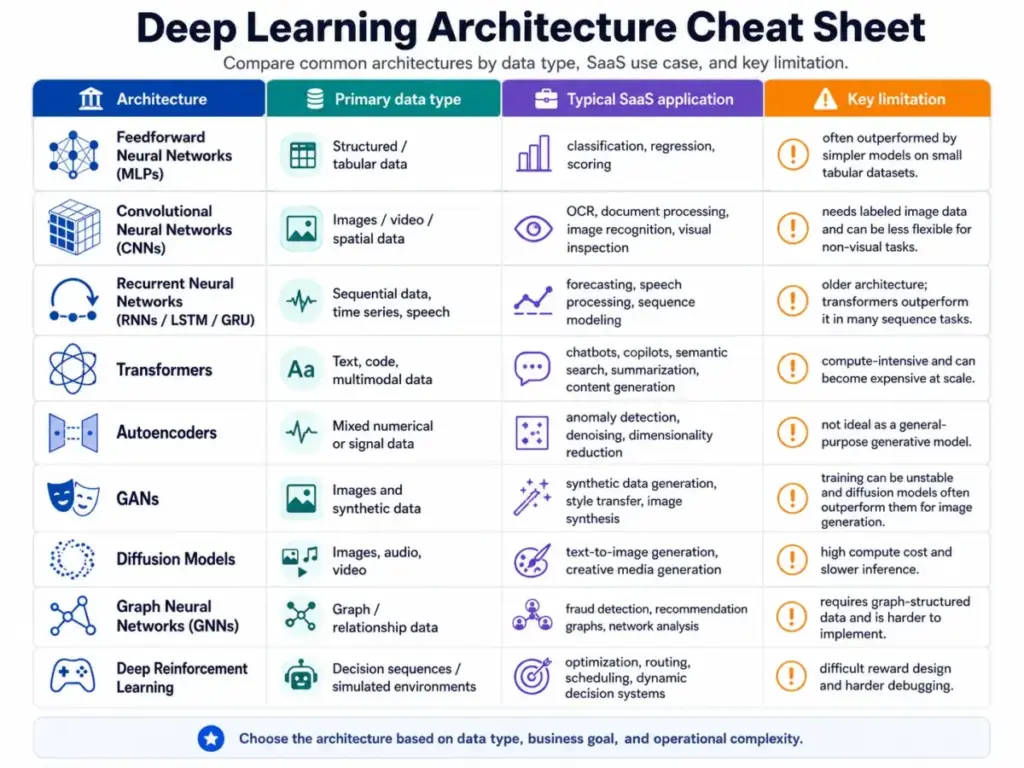
Types of Deep Learning Models
Not every deep learning model works the same way. The architecture determines what kind of data it handles, which SaaS use cases it fits, and what tradeoffs you accept.
| Architecture | Data type | SaaS use case examples | Buyer caveat |
|---|---|---|---|
| Convolutional neural networks (CNNs) | Images, video, spatial data | Visual inspection, medical imaging, document OCR, product image search | Needs labeled image datasets; less flexible than vision transformers for some tasks |
| Transformers | Text, code, multimodal | Chatbots, copilots, semantic search, summarization, code generation, NLP | Compute-intensive; token costs scale with usage |
| Recurrent neural networks (RNNs/LSTM/GRU) | Sequences, time series, speech | Demand forecasting, speech-to-text, sensor monitoring | Historically important; transformers now dominate many sequence tasks |
| Autoencoders | Any (learns compressed representations) | Anomaly detection, data denoising, dimensionality reduction | Not generative by default; often a preprocessing step |
| Generative adversarial networks (GANs) | Images, synthetic data | Synthetic training data, style transfer | Training instability; largely superseded by diffusion models for image generation |
| Diffusion models | Images, audio, video | Text-to-image AI, audio synthesis, video generation | High compute cost for generation; slow inference without optimization |
| Graph neural networks (GNNs) | Network/relationship data | Fraud ring detection, recommendation graphs, supply chain analysis | Requires graph-structured data; niche but valuable |
| Deep reinforcement learning | Decision sequences | Logistics optimization, game AI, robotics, resource scheduling | Hard to debug; reward function design is critical |
| Feedforward neural networks (MLPs) | Tabular, structured | Classification, regression, feature combination | Often outperformed by gradient-boosted trees on small tabular data |
The architecture table matters because it prevents a common buyer mistake: assuming all AI features use the same technology. A vendor’s image recognition feature (CNN or vision transformer) has completely different data requirements, cost drivers, and failure modes than their chatbot feature (transformer-based LLM).
The Cost of Getting Deep Learning Wrong
Most deep learning explainers tell you the concept works. Few explain what happens when it does not, or what the bill looks like when it does.
Where costs come from
Deep learning costs extend well beyond the model itself. Based on official documentation from the platforms covered in this guide, production AI costs include:
- Training compute: GPU or TPU hours during model training. Costs scale with model size, data volume, and training duration.
- Inference compute: Every prediction or generation consumes compute resources. High-traffic features create ongoing infrastructure costs.
- Data pipelines: Storage, preprocessing, labeling, and data governance all have costs.
- Monitoring and operations: Drift detection, performance tracking, retraining, rollback systems, and incident response.
- Human review: High-risk outputs require human verification, especially in regulated or safety-critical contexts.
- Idle capacity: GPU instances that sit unused between inference requests still cost money.
- Governance and compliance: Audit logs, access controls, model documentation, and regulatory reporting.
Platform pricing reality
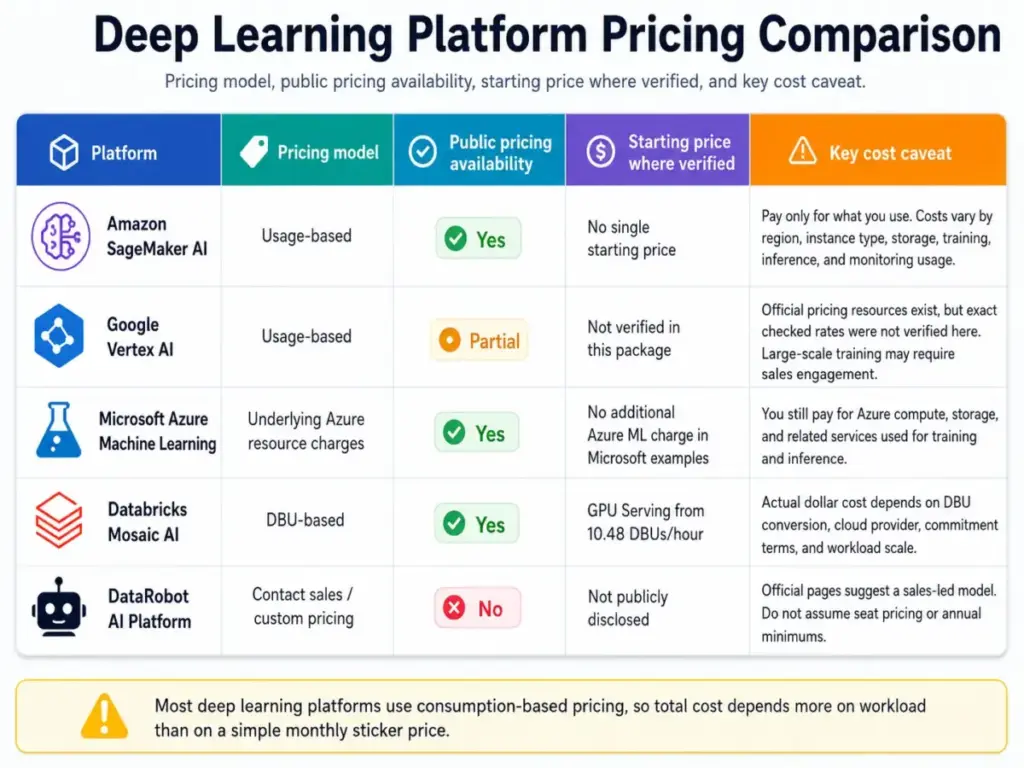
If you are evaluating platforms to build, train, or deploy deep learning models, here is what the pricing reality looks like (as of May 2026):
| Platform | Pricing model | Starting price | Key caveat |
|---|---|---|---|
| Amazon SageMaker AI | Usage-based (compute, storage, training, inference, MLOps) | No single starting price; pay for what you use | Costs vary by region, instance type, feature, and duration; Free Tier available with limited hours |
| Google Vertex AI | Usage-based (custom training, serving, AutoML, generative AI) | Pricing resources available but exact rates not verified in this package | Google provides pricing documentation; contact sales for large-scale training clusters |
| Microsoft Azure Machine Learning | Underlying Azure resource charges | No additional Azure ML charge in Microsoft examples; VM and compute costs apply | Total costs depend on Azure VMs and services consumed during training and inference |
| Databricks Mosaic AI | DBU-based (Databricks Units) | GPU Serving starts at 10.48 DBUs/hour for small T4 instance | Dollar costs depend on DBU rate, cloud provider, commitment terms, and workload |
| DataRobot AI Platform | Contact sales / custom pricing | Not publicly disclosed | Try-for-free and demo paths available; contact sales for enterprise pricing |
What this means: None of these platforms have a simple monthly price you can compare on a spreadsheet. Every one of them charges based on what you consume: compute type, training duration, inference volume, storage, and feature usage. Before committing to any platform, run a cost projection for your specific workload. The marketing page price is never the full picture.
Common Misconceptions About Deep Learning
Misconceptions about deep learning cost SaaS buyers real money. They lead to over-buying, under-governing, and misplaced expectations. Here are the five I encounter most often.
Misconception: Deep learning and artificial intelligence are the same thing.
Reality: Deep learning is a subset of machine learning, which is itself a subset of AI. Some AI systems use rules, statistical models, or optimization algorithms with no neural networks involved. When a vendor labels a feature “AI-powered,” it could mean anything from a hard-coded rule to a transformer model. Ask what is actually under the hood.
Misconception: Deep learning always beats traditional machine learning.
Reality: Deep learning excels on large, complex, unstructured data. But for small, structured, tabular business datasets, simpler models like gradient-boosted trees or logistic regression often perform as well or better, train faster, cost less, and produce more interpretable results. Choosing deep learning because it sounds more advanced is not a strategy.
Misconception: The model learns like a human brain.
Reality: Neural networks are inspired by the concept of layered processing in biological systems, but they are mathematical functions trained on data, not cognition. They do not understand context the way humans do. They find statistical patterns and generalize from examples. This matters because it explains why deep learning models can be confidently wrong and why human review remains necessary for high-stakes decisions.
Misconception: Once a model is trained, the hard work is over.
Reality: Training is maybe 20% of the effort. Production deep learning systems need deployment infrastructure, monitoring for accuracy and drift, security controls, cost tracking, retraining schedules, governance documentation, and rollback paths. The teams that treat training as the finish line are the ones surprised by production failures three months later.
Misconception: Deep learning removes the need for humans.
Reality: Humans still define the business problem, curate training data, evaluate model outputs, set risk thresholds, decide where automation is acceptable, and intervene when the model fails. Deep learning changes what humans do, not whether humans are needed.
| Misconception | Reality | Buyer implication |
|---|---|---|
| DL = AI | DL is one method within the AI hierarchy | Ask vendors what technique a feature actually uses |
| DL always wins | Simpler models often beat DL on structured data | Do not pay for DL complexity you do not need |
| Models learn like brains | Mathematical pattern matching, not cognition | Expect confident errors; build human review |
| Training is the hard part | Production ops is 80% of the effort | Budget for monitoring, drift detection, retraining |
| DL replaces humans | DL changes human tasks, not human necessity | Plan for human-in-the-loop governance |
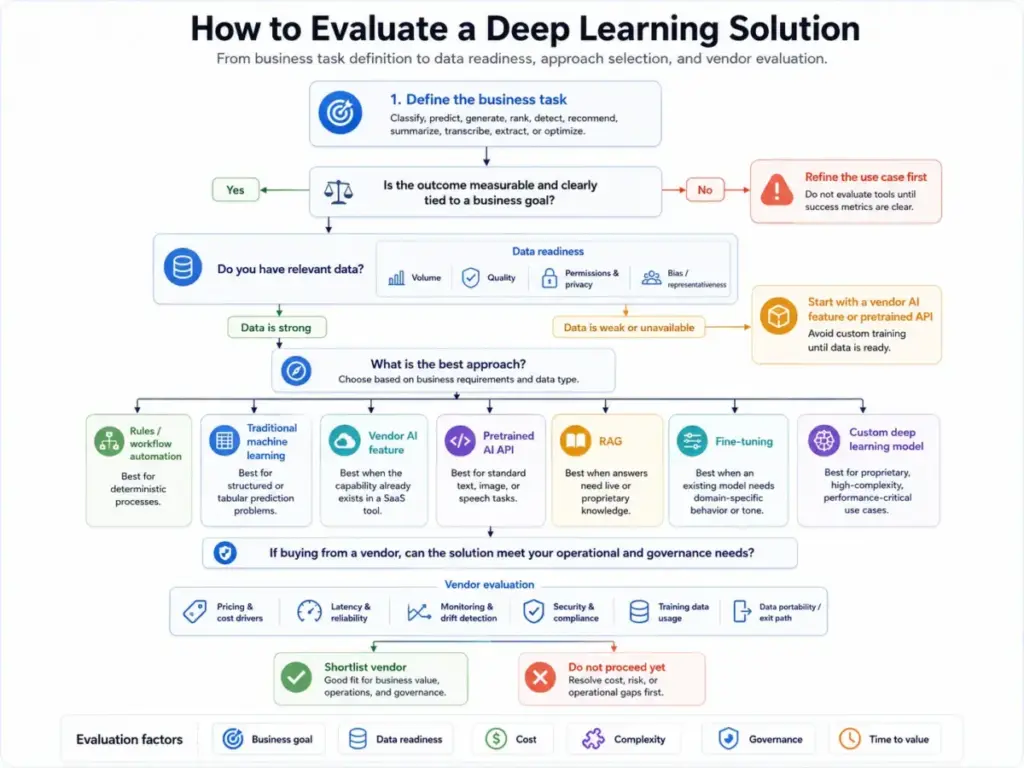
How to Evaluate Deep Learning Solutions
Whether you are building deep learning models in-house or buying SaaS products that use them, here is a weighted evaluation framework.
Step 1: Define the business task in measurable terms
Classify, predict, generate, rank, detect, recommend, summarize, transcribe, extract, or optimize. If you cannot state the task in one sentence with a measurable outcome, you are not ready for deep learning.
Step 2: Decide whether deep learning is actually needed
Compare the problem against simpler options: rules, analytics, classic machine learning, pretrained APIs, and foundation-model APIs. If a rules-based workflow or a gradient-boosted tree solves 90% of the problem at 10% of the cost, start there. You can always add deep learning later.
Step 3: Inventory your data
Confirm data volume, labeling quality, permissions, privacy constraints, bias risks, retention limits, and update frequency. Deep learning is data-hungry. If your training data is small, poorly labeled, or legally restricted, the model will underperform regardless of architecture.
Step 4: Choose your approach
| Approach | When to use | Typical cost | Complexity |
|---|---|---|---|
| Vendor AI feature (built-in) | Feature exists in a tool you already use | Included or plan-gated | Low |
| Pretrained API (OpenAI, Google, etc.) | Standard tasks like classification, summarization, generation | Per-token or per-call | Low to medium |
| Fine-tuned foundation model | Need domain-specific behavior from a pretrained base | Moderate compute + data prep | Medium |
| Custom-trained model | Unique problem with proprietary data | High compute + MLOps investment | High |
| Hybrid system with RAG | Need grounded, up-to-date outputs from an LLM | Moderate (retrieval + generation) | Medium to high |
Step 5: Evaluate the platform or vendor
Ask these questions before signing anything:
- What data does the AI feature train on? Is customer data used for model training?
- What is the model update and retraining cadence?
- What latency should we expect for inference?
- What are the failure modes and how does the system handle errors?
- What audit logs, access controls, and compliance documentation are available?
- What happens to our data if we leave the platform?
- Is the pricing usage-based, and what are the cost drivers at our expected volume?
- What monitoring and drift detection is built in?
- Is there a human review workflow for high-risk outputs?
Step 6: Set baselines before training or deploying
Compare against a simple model, a manual workflow, or the current process. If the deep learning approach does not measurably improve outcomes, it is adding cost without value.
When to Use Deep Learning and When to Avoid It
Use deep learning when
- The problem involves high-volume complex or unstructured data (text, images, audio, video)
- Pattern recognition is required at a scale where manual rules fail
- You need generative AI output (natural language, images, code)
- Transfer learning or foundation-model workflows reduce training requirements
- You have sufficient labeled data, compute budget, and monitoring capability
- The business impact justifies the cost and complexity
Avoid deep learning when
- The dataset is tiny or purely tabular (simpler ML models are cheaper and often better)
- The workflow is deterministic and rules-based
- Every output must be fully explainable for regulatory or legal compliance
- Latency or compute budgets are strict and cannot absorb GPU costs
- Labels are poor, biased, or insufficient
- The team cannot monitor, retrain, and govern the model post-launch
- A vendor AI feature or pretrained API already solves the problem
The gap between “can we use deep learning?” and “should we use deep learning?” is where most wasted spend happens. I have seen teams invest six months in custom model training when a $20/month vendor API call would have delivered 95% of the value. The technology is impressive. The business case has to be equally strong.
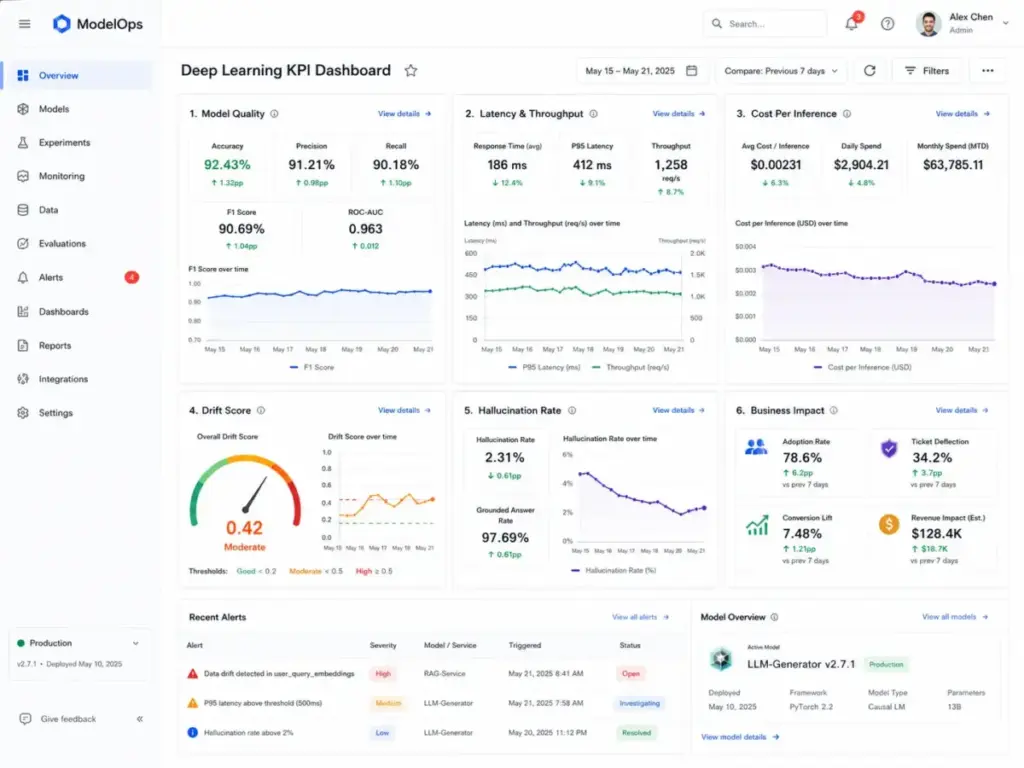
How to Measure Deep Learning Success
Measuring deep learning is not just about model accuracy. It is about five dimensions that together determine whether the investment is worthwhile.
| Category | Metric | Why it matters |
|---|---|---|
| Model quality | Accuracy, precision, recall, F1 score, ROC-AUC, mean absolute error | Core performance indicators. Low scores mean the model is not solving the problem. |
| Operations | Latency, throughput, GPU utilization, drift score, rollback frequency | Production health. High latency frustrates users. Undetected drift degrades outputs silently. |
| Cost | Cost per inference, cost per training run, total monthly compute spend | Financial sustainability. AI features that cost more than they generate are liabilities. |
| Risk | Hallucination rate, grounded-answer rate, false positive rate, false negative rate, human escalation rate, compliance incidents | Governance health. In regulated industries, a single undetected failure can be more expensive than the entire project. |
| Business impact | User adoption, conversion lift, churn reduction, ticket deflection, revenue impact | The final measure. If the deep learning feature does not move a business metric, the technical metrics are academic. |
What this means: If your vendor only reports model accuracy and ignores cost, drift, and business impact metrics, you are flying blind. Ask for dashboards that cover all five dimensions, or build them yourself.
Deep Learning Tools and Platform Examples
The following platforms support building, training, deploying, and monitoring deep learning models at production scale. These are not the only options, but they represent the major cloud-native approaches SaaS teams evaluate.
Amazon SageMaker AI
A fully managed ML service for building, training, and deploying models on AWS infrastructure. SageMaker supports bring-your-own frameworks, distributed training, hosted notebooks, feature store, pipelines, and model monitoring. Pricing is usage-based across compute, storage, processing, and deployment, with a Free Tier that includes limited training and inference hours. Best fit for teams already invested in the AWS ecosystem that need end-to-end ML lifecycle tooling.
Google Vertex AI
A unified Google Cloud AI platform with generative AI, Model Garden, embeddings, AutoML, custom training jobs, hyperparameter tuning, distributed training with TPU and GPU support, and MLOps integrations. Vertex AI supports TensorFlow, PyTorch, scikit-learn, XGBoost, and custom containers. Foundation models can be customized through supervised tuning. Google provides pricing documentation, though exact rates should be verified directly.
Microsoft Azure Machine Learning
Enterprise ML lifecycle tooling for training and deploying models with MLOps best practices and Azure compute integration. Azure Machine Learning may have no additional platform charge in Microsoft’s examples, but customers pay for underlying Azure resources (VMs, storage, networking) used during training and inference. Best fit for Microsoft-centric organizations that need responsible AI workflows and enterprise governance.
Databricks Mosaic AI
Built for data teams that want to train, fine-tune, serve, and govern models close to enterprise lakehouse data. Mosaic AI supports fine-tuning smaller open-source LLMs, training models from scratch, and GPU-based model serving. Pricing is DBU-based, with GPU Serving starting at 10.48 DBUs/hour for a small T4-equivalent instance. Actual dollar costs depend on cloud provider, commitment terms, and workload pattern.
DataRobot AI Platform
Enterprise AI tooling for predictive and generative AI, including model development, LLM and embedding model selection, GPU access, evaluation, deployment, monitoring, governance, and cost and latency tracking. DataRobot supports cloud, on-premise, virtual private cloud, and SaaS deployment. Pricing follows a sales-led or custom model; contact the sales team for enterprise pricing.
Deep Learning Implementation Checklist
Use this before building or buying any deep learning capability:
- [ ] Business task is defined in measurable terms
- [ ] Deep learning is confirmed as necessary (simpler alternatives evaluated)
- [ ] Data sources inventoried: volume, quality, labels, permissions, privacy, bias
- [ ] Approach selected: vendor feature, pretrained API, fine-tune, custom model, or hybrid
- [ ] Architecture chosen based on data type and use case
- [ ] Baseline established: simple model or manual workflow for comparison
- [ ] Evaluation metrics defined across quality, operations, cost, risk, and business impact
- [ ] Deployment plan includes monitoring, drift detection, and rollback
- [ ] Governance covers access controls, audit logs, human review thresholds, and compliance
- [ ] Retraining schedule and data lineage documented
- [ ] Cost projection completed for expected inference volume and training cadence
- [ ] Vendor questions asked: training data usage, model updates, latency, failure handling, data portability
FAQ
What is deep learning in simple terms?
Deep learning is a way to teach computers to recognize patterns in complex data like text, images, and audio by processing it through layers of artificial neurons. Each layer detects increasingly abstract patterns. The result is a model that can classify, predict, or generate outputs without being explicitly programmed for every scenario.
What is the difference between AI, machine learning, and deep learning?
AI is the broadest category: any system that performs tasks typically requiring human intelligence. Machine learning is a subset of AI where systems learn from data. Deep learning is a subset of machine learning that uses multilayered neural networks. Think of it as nested circles: AI contains ML, and ML contains deep learning.
Is deep learning always better than traditional machine learning?
No. Deep learning performs best on large, complex, unstructured data. For small structured datasets, simpler algorithms like gradient-boosted trees, random forests, or logistic regression often match or outperform deep learning at a fraction of the cost and complexity. Choose based on the problem, not the buzzword.
How much data does deep learning need?
It depends on the task and architecture. Transfer learning and fine-tuning pretrained foundation models can work with thousands of examples. Training a model from scratch on a specialized task might need millions. The quality of labels matters as much as quantity. Noisy or biased data produces unreliable models regardless of volume.
Why does deep learning need GPUs?
Neural network computation is highly parallel: thousands of matrix multiplications happen simultaneously during training. GPUs (and TPUs) are designed for parallel computation, which makes them dramatically faster than CPUs for training deep learning models. For inference, some models can run on CPUs, but GPU-accelerated inference reduces latency for production workloads.
Can small companies use deep learning without building models from scratch?
Yes. Most small companies should use pretrained APIs (like those from OpenAI, Google, or Anthropic), vendor-built AI features in their existing SaaS tools, or fine-tuned foundation models. Building from scratch requires data, compute, and MLOps capabilities that most small teams lack.
What is the difference between training and inference in deep learning?
Training is the process of teaching the model by feeding it data and adjusting weights to minimize errors. It is computationally expensive and typically done periodically. Inference is using the trained model to process new inputs and produce outputs. It happens every time a user interacts with an AI feature. Training costs are upfront; inference costs are ongoing.
Should I fine-tune a model or use RAG?
Fine-tuning adjusts a pretrained model’s weights using your data, changing its behavior permanently. RAG retrieves relevant documents at query time and feeds them to the model as context. Use fine-tuning when you need the model to consistently behave differently (style, domain terminology, format). Use RAG when you need the model to access up-to-date information it was not trained on. Many production systems combine both.
What are the risks of using deep learning in regulated industries?
The main risks are interpretability (deep learning models are often black boxes), data privacy (training data may contain sensitive information), bias (models can amplify biases present in training data), and accountability (determining responsibility when an automated decision causes harm). Regulated industries should require audit logs, human review thresholds, explainability documentation, and compliance certifications from any deep learning vendor.
How do I explain deep learning to non-technical executives?
Frame it in business terms: deep learning is the technology that enables specific product capabilities your team uses or evaluates, like chatbots, fraud detection, document processing, and recommendations. It requires data, compute, and ongoing monitoring. The executive decision is not whether deep learning works (it does), but whether a specific deep learning feature is worth its cost, risk, and governance burden for your business.





