
A large language model is the engine behind tools like ChatGPT, Claude, Gemini, and Perplexity — but the business value depends on how well you understand its limits. This guide explains what a large language model is, how it predicts language, where it helps SaaS teams, and when a smaller automation tool beats an AI chatbot.
I cover the mechanics without the math, map use cases to actual teams, and point you to the best AI tools worth evaluating once you understand what the technology does and does not do. If you want the broader context first, the what is artificial intelligence guide covers the parent category.
What Is a Large Language Model?
A large language model is a type of deep learning model trained on massive text datasets to understand and generate human language. LLMs are a specific implementation within the broader field of natural language processing. According to IBM, LLMs are deep learning models trained on immense amounts of data that typically use transformer architecture. According to Cloudflare, LLMs are machine learning models that comprehend and generate human-language text.
The definition matters less than the distinction. Here is a reference table for the terms you will encounter:
| Term | What It Is | Real Example | Common Mistake |
|---|---|---|---|
| Large language model | A trained neural network that predicts and generates text | GPT-4o, Claude 3.5, Gemini 1.5 Pro | Treating the model itself as a product |
| AI chatbot | A product interface built around an LLM | ChatGPT, Claude.ai, Gemini app | Treating the chatbot as the model |
| Generative AI | A broader category of AI that generates content | Text, image, audio, video generation | Assuming all generative AI is language-based |
| Foundation model | A large pretrained model adaptable to many tasks | GPT-4o, Gemini Ultra, Llama 3 | Treating every AI model as a foundation model |
| AI agent | A system that uses an LLM as a reasoning engine to take actions | Coding assistants, workflow agents | Assuming agents are autonomous and reliable by default |
| RAG system | A setup that connects an LLM to external documents or databases | Perplexity, enterprise knowledge tools | Assuming the model already knows your internal data |
ChatGPT is not the LLM itself. It is a product interface built by OpenAI around their GPT-series models. The LLM is the underlying engine. The chat interface is the product wrapper. Keeping that distinction clear prevents a category of bad buying decisions.
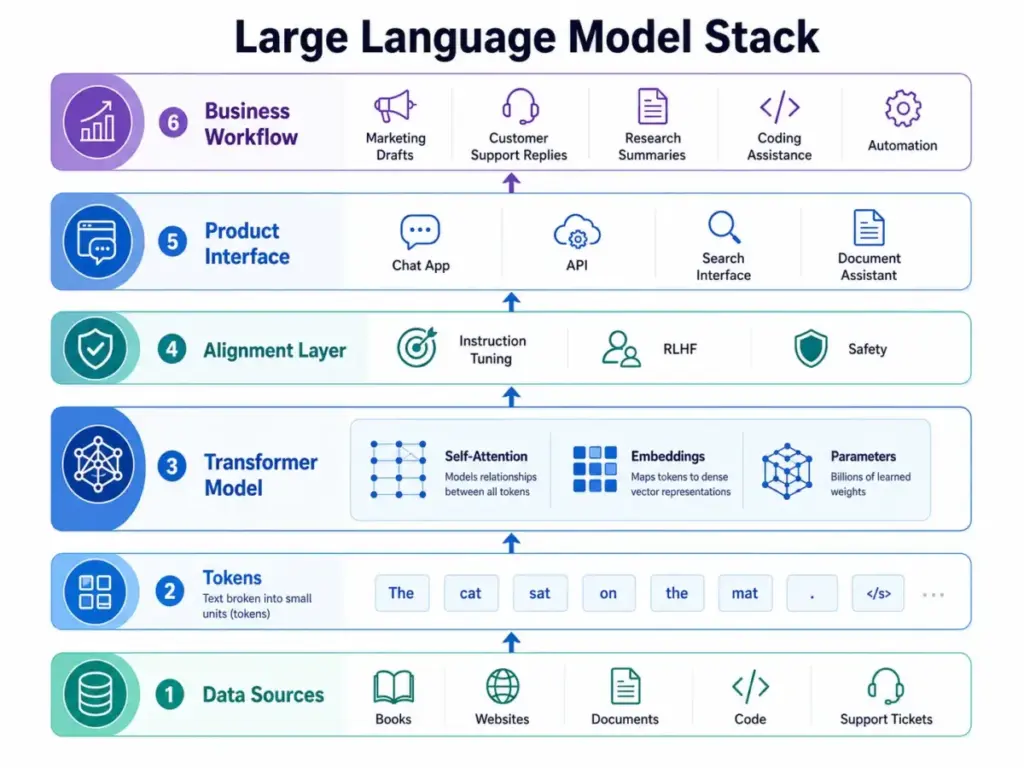
How Does an LLM Work?
The short answer is that a large language model predicts the most statistically probable next piece of text, one token at a time, based on patterns learned from enormous amounts of training data. That sounds too simple to explain useful outputs. The fuller picture requires five connected concepts.
Training Data and Tokens
LLMs are trained on text collected from books, websites, code repositories, research papers, and other sources. The model never reads raw words. It reads tokens, which are chunks of text — sometimes a full word, sometimes a word fragment, sometimes punctuation. Tokenization converts human text into a sequence of numeric IDs the model can process.
Embeddings and Parameters
Each token is converted into an embedding: a vector of numbers representing the token’s meaning in relation to all other tokens the model has seen. The model learns these relationships by adjusting its parameters during training. According to Brown et al., 2020, GPT-3 contained 175 billion parameters. Parameters store the statistical patterns that make the model capable of language tasks. More parameters generally allow more nuance, but model quality depends on training data, alignment methods, and architecture — not parameter count alone.
The Transformer and Self-Attention
Modern LLMs use transformer architecture, published in 2017 by Vaswani et al. at Google. The paper states:
“We propose a new simple network architecture, the Transformer, based solely on attention mechanisms.” — Ashish Vaswani et al., Attention Is All You Need, 2017
Self-attention lets the model weigh the relevance of every word to every other word in a sequence. When you write “The bank by the river flooded,” self-attention helps the model connect “bank” to “river” and “flooded,” not to finance. This is what allows LLMs to handle context across long passages.
Pretraining and Fine-Tuning
Pretraining is the first phase. The model reads trillions of tokens and learns broad language patterns. Fine-tuning is the second phase. The pretrained model is adapted to specific tasks or behaviors. Instruction tuning teaches the model to follow prompts. Reinforcement learning from human feedback (RLHF) shapes outputs toward responses humans prefer. As Brown et al. noted:
“Scaling up language models greatly improves task-agnostic, few-shot performance.” — Tom B. Brown et al., Language Models are Few-Shot Learners, 2020
Why Instruction-Following Emerges
A common question is: if LLMs only predict the next token, how do they follow complex instructions?
The answer is that RLHF and instruction tuning change what counts as the “probable” next token. The model is trained with feedback that rewards helpful, accurate, task-aligned responses. The autocomplete mechanism is still there. The feedback loop shapes what “good next tokens” look like. The model does not reason the way a person reasons. It produces statistically shaped output. That distinction matters for understanding both its capabilities and its limits.
Inference
Inference is what happens after training: the model generates output in response to your input. Every output is a new prediction process. The model has no persistent memory across sessions unless the product layer stores it.
Why Do Large Language Models Matter?
For SaaS teams, large language models matter because they unlock a class of text-based automation that was too expensive, slow, or inconsistent to scale with human labor alone. The business case is not that LLMs are intelligent. It is that they can produce useful first drafts, summaries, translations, and structured outputs at a speed and volume that humans cannot match.
A practical example: a customer support team uses an LLM to draft responses to common questions. The model pulls from a knowledge base, produces a draft, and queues it for a human agent to review and send. The human still handles refunds, account-specific judgment, and escalations. The LLM handles the first draft of the routine 60%. That is a concrete, bounded, measurable use case. It is different from handing the model free-form access to customer conversations and assuming accuracy.
The distinction between “LLM as draft assistant” and “LLM as decision maker” is where most failed deployments originate.
Types of Large Language Models
Not all LLMs are the same product category, and confusing model type with product packaging leads to poor vendor decisions.
General-Purpose LLMs
General-purpose LLMs are pretrained on broad datasets and fine-tuned to handle a wide range of tasks: writing, coding, analysis, summarization, translation, and conversation. GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro fall into this category. Most SaaS teams start here.
Domain-Specific LLMs
Domain-specific LLMs are fine-tuned on data from a narrow vertical: legal documents, medical records, financial filings, or code. They trade general capability for specialized accuracy in the target domain. Examples include code-focused models like DeepSeek Coder and biomedical models like Med-PaLM. Most small SaaS teams do not build or train these. They evaluate whether a general-purpose LLM with a good system prompt covers their domain need before purchasing a specialized solution.
Open Source LLMs
Open source LLMs, such as Meta Llama 3 and Mistral 7B, release model weights publicly. Teams can run them locally or on private cloud infrastructure. The benefit is data privacy and no per-token cost at inference. The trade-off is infrastructure cost, maintenance, and the need for technical capacity to deploy and update the model. For a small business, the total cost of ownership often exceeds a subscription plan.
Closed Source LLMs
Closed source LLMs are accessed via API or product subscription. OpenAI’s GPT models, Anthropic’s Claude, and Google’s Gemini are closed source. The vendor handles training, maintenance, and safety alignment. The trade-off is that your data passes through their infrastructure, and pricing scales with usage.
Multimodal LLMs
Multimodal LLMs process more than text. They handle images, audio, video, or documents alongside text prompts. GPT-4o and Gemini Ultra are multimodal. For SaaS teams that process PDFs, screenshots, or recorded calls, multimodal capability matters. For text-only workflows, it is a feature you pay for whether or not you use it.
Retrieval-Augmented LLM Systems
A RAG system connects an LLM to an external knowledge source at inference time. The model does not need to have been trained on your company documents. It retrieves relevant chunks from a database and uses them as context when generating a response. Perplexity uses a version of RAG to ground answers in real-time web search results. Enterprise tools use RAG to connect LLMs to internal wikis, CRMs, and policy documents. For business knowledge workflows, RAG often matters more than raw model size.
Large Language Model Use Cases
LLM use cases differ significantly by team function, and the right tool depends on the task type, source requirements, and tolerance for output error.
The table below maps use cases to team functions and flags where human review is non-negotiable.
| Team | LLM Use Case | Better With RAG? | Human Review Needed? | Example Tool |
|---|---|---|---|---|
| Marketing | First drafts, outlines, content repurposing | Optional | Recommended | ChatGPT, Claude |
| Support | Response drafts, knowledge article lookup | Yes | Always | Claude, AI chatbot platforms |
| Sales | Email drafts, call summaries, objection prep | Optional | Recommended | ChatGPT, Gemini |
| Product | Feedback clustering, PRD draft generation | Yes | Always | Claude, Gemini |
| Engineering | Code explanation, test generation, review | No | Recommended | ChatGPT, GitHub Copilot |
| Operations | Policy search, meeting summaries, SOP drafts | Yes | Recommended | Perplexity, Claude |
| Research | Source-assisted answers, citation triage | Yes | Always | Perplexity |
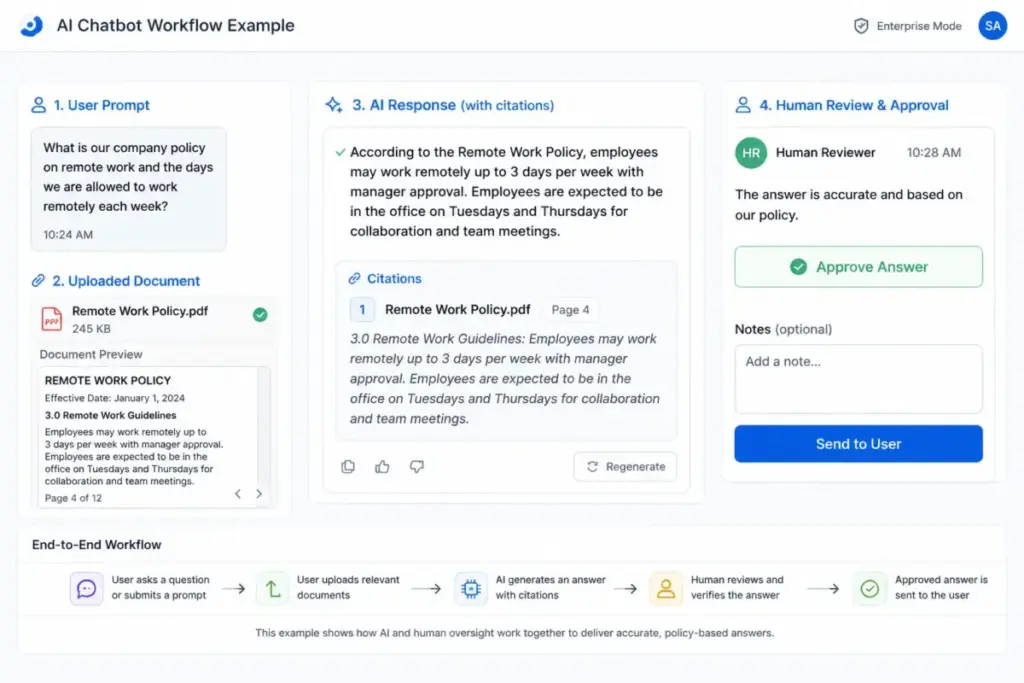
Benefits of Large Language Models
The benefits of large language models are real, but each one comes with a condition that determines whether the benefit materializes for your team.
Faster first drafts. LLMs reduce the time from blank page to draft in marketing copy, email sequences, support replies, and documentation. The condition: the draft still needs human review before it reaches a customer or goes live.
Lower support writing load. Support teams spend significant time drafting variations of the same response. An LLM with a well-structured knowledge base can handle routine response drafts. The condition: routing logic and escalation rules must be defined before deployment.
Better knowledge access. With RAG, LLMs can surface information from internal documents faster than manual search. The condition: the source documents must be accurate, current, and correctly indexed.
Code assistance. Engineers use LLMs to explain unfamiliar code, generate boilerplate, write tests, and review logic. According to NVIDIA, LLMs recognize, summarize, translate, predict, and generate content using large datasets. The condition: generated code must be reviewed by a developer before merging.
Multilingual support. LLMs produce reasonable translations and multilingual drafts, reducing the cost of serving non-English-speaking customers. The condition: sensitive or legal content still requires a qualified human translator.
Faster research triage. LLMs with search capabilities, such as Perplexity, can summarize and organize research sources faster than manual browsing. The condition: every cited fact must be verified against the original source before publishing.
Workflow automation with human review. When connected to workflow tools, LLMs can trigger actions, classify inputs, and route tasks. The condition: the automation must include a human checkpoint for any output that affects a customer, a payment, or a compliance obligation.
Challenges and Limitations
Large language models have well-documented failure modes that SaaS teams regularly underestimate before deployment.
Hallucination
Hallucination means the model generates output that is plausible in structure but unsupported or false in fact. The model does not know what it does not know. It generates the statistically probable next token regardless of whether that token is accurate. This is not a bug in the traditional sense. It is a structural property of the architecture. High-stakes outputs — regulatory advice, financial calculations, citation-critical research — require verified sources, not model confidence.
Privacy and Confidential Data
When you send text to a closed-source LLM via an API or product interface, that text passes through the vendor’s infrastructure. Enterprise plans for OpenAI, Anthropic, and Google include data processing agreements and controls, but free and standard-tier accounts may use inputs for model improvement depending on the provider’s current terms. Teams handling customer PII, financial records, or proprietary strategy need to verify the data terms before using any LLM product for those workflows.
Bias
LLMs reflect patterns in training data. If the training data contains biases, the model output may replicate or amplify them. This is particularly relevant for hiring tools, customer scoring, and any output that affects decisions about people.
Outdated Knowledge
Closed-source LLMs have a training data cutoff. Events, products, or information after that cutoff are unknown to the base model. A RAG system or a model with real-time search access, such as Perplexity, partially addresses this, but the base model’s knowledge remains static.
Unclear Sources
Most LLMs do not cite sources by default. They synthesize information without attribution. For publishing, research, and compliance work, unsourced outputs create liability and accuracy risks. RAG systems that surface document references reduce but do not eliminate this problem.
Cost and Token Usage
For a concrete example of this subscription-versus-API split, see the Moonshot AI review, which breaks down Kimi membership gates and token-based API costs. Longer context windows mean more tokens processed, which increases cost per call. A large document passed as context in every API call adds up quickly.
Subscription plans for ChatGPT, Claude, Gemini, and Perplexity simplify pricing but still have usage limits and model-access tiers. For example, OpenAI, Anthropic, Google, and Perplexity all publish API pricing separately from their subscription plans. Enterprise pricing for all four requires direct contact with their sales teams. Teams building internal tools on LLM APIs must model token costs before committing.
Context Window Limits
Every LLM has a context window: the maximum amount of text the model can consider in a single input-output exchange. A model with a 128,000-token context window can process roughly 100,000 words at once. Beyond the window, earlier content is dropped. For teams analyzing long documents or maintaining conversation history, context length is a practical constraint that determines which model is appropriate.
Security and Governance
NIST treats generative AI risk management as a cross-sector concern. The NIST AI Risk Management Framework states:
“The AI RMF was released in January 2023, and is intended for voluntary use.” — NIST, AI Risk Management Framework: Generative Artificial Intelligence Profile, 2024
The NIST framework covers design, deployment, evaluation, and use-phase risks, including adversarial prompts, data poisoning, and model misuse. Teams deploying LLMs in customer-facing or compliance-adjacent workflows should treat the NIST AI RMF as a baseline governance reference, not a ceiling.
Overreliance
The most common and least technical risk is overreliance. Teams that accept model output without review, treat model confidence as accuracy, or deploy LLMs in workflows that require deterministic outputs will encounter errors that a rule-based system would have prevented.
When an LLM Is the Wrong Tool
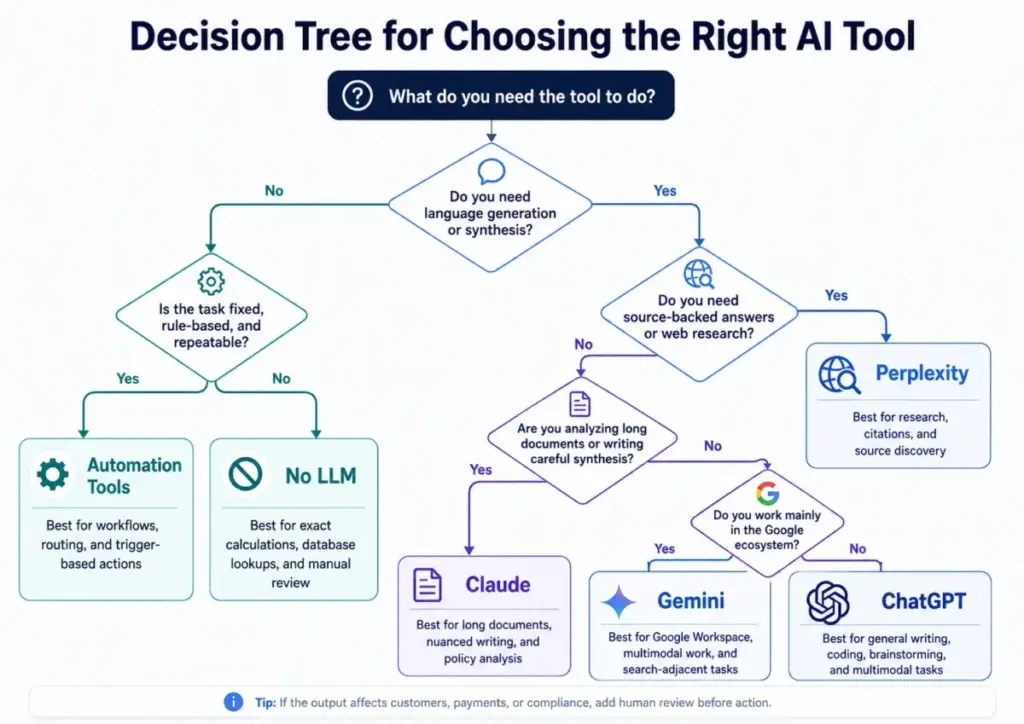
An LLM is often a worse choice than a rules-based system when the task has fixed inputs, fixed outputs, and zero tolerance for variation.
This section exists because the reverse — when LLMs are over-promoted — is common in SaaS marketing.
Deterministic calculations. Tax computation, pricing engines, and financial reporting require exact outputs. An LLM produces probabilistic outputs. Use a calculation engine, not a language model, for anything where the answer is verifiable and must match a fixed result.
Compliance decisions without expert review. An LLM will produce a confident-sounding response to a legal, medical, or financial query. That response is not regulated advice. Any compliance decision that requires a licensed professional cannot be delegated to an LLM without a human expert in the review chain.
High-volume repeatable automation. If you have a workflow with structured inputs and structured outputs — parsing an invoice, triggering a status update, routing a support ticket by category — a rules-based automation tool or a purpose-built integration handles it more reliably and at lower cost than an LLM call.
Private customer data without controls. If your use case requires sending customer PII, financial records, or confidential contracts to a language model, and you do not have a data processing agreement with the vendor, the LLM is the wrong tool until you resolve the governance issue.
Source-critical research without citations. If the output will be published and attributed, or used in a compliance document, and you cannot trace the source, an LLM without RAG is the wrong tool. Use a tool that surfaces citations.
Simple if-this-then-that workflows. If a human can write the logic as a decision tree in ten minutes, an LLM adds latency, cost, and error variance for no benefit.
Exact database lookups. An LLM cannot reliably query a structured database unless connected to a tool that does the query for it. For data retrieval tasks with exact field matches, use a database query, not a language model.
LLM vs Generative AI vs Chatbot
These three terms are used interchangeably in most marketing, and they should not be.
| Term | Meaning | Example | Common Mistake |
|---|---|---|---|
| LLM | A trained deep learning model for language tasks | GPT-4o, Claude 3.5, Llama 3 | Treating it as a product you subscribe to |
| Generative AI | A category of AI that produces content | Text, images, audio, video, code | Using it as a synonym for LLM |
| AI chatbot | A product interface using an LLM for conversation | ChatGPT, Claude.ai app, Gemini | Treating the interface as the model |
The LLM is the engine. Generative AI is the category the engine belongs to. The chatbot is the car. Most business decisions are about the car, but the engine type determines what the car can do.
Reviewing AI chatbot software alongside the LLM that powers each product gives a more complete picture than comparing chatbot interfaces alone.
How to Choose an LLM Tool
The right LLM tool depends on your workflow type, not on which model scores highest on a benchmark.
Use this framework before committing to a subscription or API contract:
Task type. Is the output going to customers, internal teams, or automated pipelines? Tasks going to customers need stricter review and sourcing. Automated pipelines need deterministic formatting. Internal drafts allow more tolerance for imperfect output.
Source requirements. If your output must cite sources, use a tool with RAG or search integration. If you are generating original content, a base model with a good system prompt is sufficient.
Privacy controls. What data are you sending? Free and standard plans often have different data terms than enterprise agreements. Verify the vendor’s data processing policy before connecting the tool to customer data.
Context length. If you process long documents, contracts, or transcripts, context window size directly affects whether the model can handle the task in a single call.
Model quality for your use case. Model benchmarks are general. Your use case may favor one model over another independent of overall rankings. Evaluate with your actual prompts and data before committing.
Citation needs. Marketing and internal drafts often do not require citations. Research outputs and published articles do. Tools like Perplexity surface sources by default. Base models like ChatGPT and Claude require explicit prompting to provide references.
Integrations. Does the tool connect to your CRM, support platform, or document storage? Native integrations reduce custom development cost.
Cost model. Subscription plans have fixed monthly costs with usage caps. API access scales with usage but requires technical setup. Evaluate total cost at your expected monthly volume, not just the advertised plan price.
Team adoption. A tool that requires significant prompting skill or technical setup will underperform compared to a simpler tool your team actually uses. Adoption is a feature.
Governance. Does your industry have data handling requirements? Healthcare, finance, and legal sectors need vendors with specific compliance certifications (SOC 2, HIPAA BAA, GDPR DPA).
Best Tools Using Large Language Models
This section maps tools to use cases. It is not a ranking. Each tool deserves evaluation against your specific workflow. I have reviewed most of these for SaaS Zap, and the reviews follow our review methodology.
ChatGPT (OpenAI). The most widely adopted LLM product. Strong for general writing, analysis, code generation, and multimodal tasks. Available on chatgpt.com with a free tier and paid plans starting with ChatGPT Plus. The ChatGPT review covers capabilities and pricing in detail. API pricing is documented at developers.openai.com.
Claude (Anthropic). Strong for long document analysis, careful synthesis, and writing that requires tonal control. Claude’s context windows have historically been among the longest available. Available at claude.ai, with pricing at claude.com/pricing and API pricing at platform.claude.com. The Claude review covers the model tiers and limits.
Gemini (Google). Best suited for teams inside the Google ecosystem, multimodal work, and search-adjacent tasks. Integrates with Google Workspace. Available at gemini.google.com, with subscriptions at gemini.google/subscriptions and API pricing at ai.google.dev. The Gemini review covers the app and API tiers.
Perplexity. Designed for research workflows where source attribution matters. Combines LLM response generation with real-time web search. Available at perplexity.ai, with Pro plans at perplexity.ai/pro and enterprise pricing at perplexity.ai/enterprise/pricing. The Perplexity review is the best starting point for research-focused teams.
Zapier. Not an LLM product itself, but a workflow automation platform that connects LLM outputs to downstream actions. If you want ChatGPT to draft a support reply and then send it through your helpdesk, Zapier is a common connector. The Zapier review explains the integration model and pricing.
AI chatbot platforms. For customer-facing support and sales workflows, dedicated AI chatbot platforms built on LLMs handle session management, escalation logic, and CRM integration in ways that raw API access does not. The AI chatbot software hub covers the current options.
Daniel Rivera’s Quick Take
I have spent time evaluating LLM tools across SaaS workflows, and the pattern is consistent: the most useful deployments are boring. Draft the answer. Cite the source. Pass it to a human. Log the result.
Teams that get durable value from LLMs treat them as writing and synthesis assistants inside a human-reviewed process. Teams that get burned treat them as autonomous decision-makers or assume that high benchmark scores translate to accuracy in their specific use case.
The most important thing I can say about LLM adoption is this: an LLM does not need human-like understanding to be useful, but treating it like a database creates risk. A database returns the exact record you query. An LLM returns the statistically probable response to your prompt. The second behavior is powerful for drafts, summaries, and knowledge retrieval. It is dangerous for compliance decisions, financial calculations, and customer-facing communications without review.
The right question is not “Which LLM is the smartest?” The right question is “Which workflow needs probabilistic text generation, and what human checkpoint do we need before that output causes a problem?”
For most SaaS teams evaluating tools today, the answer is not the most powerful LLM. It is the LLM product with the best workflow fit, the clearest data controls, and the adoption rate your team will actually sustain.
FAQ
What is a large language model in simple terms?
A large language model is a computer system trained on enormous amounts of text that can generate, summarize, translate, and respond to human language. It works by predicting the most statistically likely next piece of text based on patterns learned during training. It does not understand language the way humans do, but it produces useful outputs across a wide range of language tasks.
Is ChatGPT a large language model?
ChatGPT is not a large language model itself. It is a product interface built by OpenAI around their GPT-series language models. The large language model is the underlying engine. ChatGPT is the product wrapper with a chat interface, usage policies, and feature packaging on top. The distinction matters when you are deciding whether you need the product subscription or direct API access to the model.
How does a large language model work?
A large language model works by converting text into tokens, mapping those tokens to numeric embeddings, processing them through a transformer architecture with self-attention, and generating output by predicting the most probable next token in sequence. During training, the model adjusts billions of parameters based on patterns in training data. After training, fine-tuning and instruction tuning shape the model’s behavior for specific tasks and safety alignment.
What is the difference between an LLM and AI?
AI, or what is artificial intelligence, is the broad field of computer systems that perform tasks that typically require human-like intelligence. An LLM is a specific type of AI system focused on language understanding and generation. All LLMs are AI, but most AI systems are not LLMs. Rule-based systems, classification models, image recognition systems, and recommendation engines are all AI without being large language models.
What is the difference between an LLM and a chatbot?
An LLM is a trained model: the statistical engine that processes and generates text. A chatbot is a product interface, often built on top of an LLM, that adds a conversational UI, session management, escalation logic, and sometimes tool integrations. Many chatbots today use LLMs as their generation engine. Earlier chatbots used rule-based decision trees that were not LLMs at all.
Why do large language models hallucinate?
LLMs hallucinate because they generate output based on statistical probability, not factual verification. The model predicts what text is most likely to follow the prompt. If a plausible-sounding but false statement is statistically probable given the training data and context, the model will generate it with apparent confidence. Hallucination is a structural property of how the model produces output, not a software bug that can be patched. Mitigation strategies include RAG, citation prompting, human review, and restricting the model to verified source material.
Are large language models trained on the internet?
Many large language models use internet text as part of their training data, including web pages, forums, books, and code repositories. The specific training data composition varies by model and vendor, and most closed-source providers do not publish full details of their training datasets. Internet data introduces both breadth of knowledge and biases present in public web content.
What are LLMs used for in business?
Common business uses include drafting marketing content, generating support response drafts, summarizing documents and meeting transcripts, writing and explaining code, translating content, clustering customer feedback, and searching internal knowledge bases. Each use case has different accuracy requirements and risk levels. Tasks involving customer-facing communications or compliance obligations require human review before output is acted upon.
Can an LLM access my private company data?
By default, a base LLM does not have access to your private data unless you provide it in the prompt or connect it to your data via a RAG system or tool integration. When you paste your data into a prompt or upload a file, that data is sent to the vendor’s infrastructure and processed according to their data terms. Enterprise agreements from OpenAI, Anthropic, Google, and Perplexity include explicit data processing provisions. Standard and free tiers should be verified separately before use with confidential information.
What is a context window?
A context window is the maximum amount of text an LLM can process in a single input-output exchange, measured in tokens. If your input exceeds the context window, the model cannot consider the full input. The model drops earlier content or returns an error depending on how the product handles the limit. Context window sizes vary by model: some handle 8,000 tokens, others handle 1 million or more. For tasks involving long documents, meeting transcripts, or extended conversations, context window size is a practical selection criterion.
What is RAG in an LLM system?
RAG stands for retrieval-augmented generation. It is a system architecture that connects an LLM to an external document source or database at inference time. When a user submits a prompt, the system retrieves relevant documents from the knowledge base and passes them as context to the model. The model generates a response grounded in the retrieved documents. RAG reduces hallucination for knowledge-specific tasks, enables citation, and allows the model to answer questions about documents it was never trained on. For business knowledge workflows, RAG is often more important than raw model capability.
Should small businesses use LLM tools?
Small businesses can get real value from LLM subscription tools for drafting, support, and research tasks, provided they keep humans in the review loop for customer-facing outputs. The main risks are overreliance on unverified outputs and using a paid subscription for tasks a simpler automation or template would handle more reliably. Start with a free tier or low-cost plan, identify one or two specific tasks where draft quality saves time, and measure actual time saved before expanding access.
Key Takeaways
- A large language model is a deep learning system that predicts and generates human language based on statistical patterns learned from training data. It is an engine, not a product.
- ChatGPT, Claude, Gemini, and Perplexity are product interfaces built on LLMs. Evaluating the interface and the underlying model separately leads to better buying decisions.
- LLMs work through tokenization, embeddings, transformer architecture, self-attention, and RLHF. You do not need to understand the math. You do need to understand that the output is probabilistic, not factual by default.
- Hallucination, outdated knowledge, privacy risk, context window limits, and cost at scale are the four failure modes that trip up most SaaS deployments. Each has a mitigation, and none should surprise you post-purchase.
- For most business knowledge workflows, a RAG system matters more than raw model size. Connecting an LLM to verified source documents produces more reliable outputs than a bigger base model without sourcing.
- An LLM is the wrong tool for deterministic calculations, compliance decisions without expert review, high-volume repeatable automation, and any workflow where a rules-based system gives the same output at lower cost and higher reliability.
- The right framework for LLM adoption is not “which model is smartest.” It is “which task needs probabilistic text generation, what is the human review checkpoint, and what happens if the output is wrong?”





