
Many teams buy AI software before they understand what is doing the learning. What is machine learning? Machine learning is a branch of artificial intelligence where software learns patterns from data and uses those patterns to make predictions, classifications, or recommendations without being manually programmed for every rule.
This guide explains how ML works in real business workflows, when it beats fixed rules, and when a simpler approach like analytics or workflow automation is the smarter choice. If you have ever wondered whether your team needs prediction, automation, or generative AI, this is where to start.
What Is Machine Learning?
Machine learning is a method for building systems that improve their output by learning from examples rather than following hand-written rules. In simple terms, ML turns examples into a reusable prediction system.
Machine learning trains a model on data, tests whether the model performs well on unseen examples, then uses that model to make predictions or classifications on new inputs. The concept traces back to Arthur Samuel’s 1959 IBM Journal work on checkers, where the goal was to “learn to play a better game of checkers.” Tom M. Mitchell later formalized the idea in 1997, defining machine learning as the ability to “automatically improve with experience” across a task, a performance measure, and training experience (source).
The key difference between ML and traditional programming: in traditional software, a developer writes rules. In machine learning, the algorithm discovers rules from data. A spam filter built with rules needs a human to define every pattern. A spam filter built with ML learns those patterns from thousands of labeled emails and adapts when spammers change tactics.
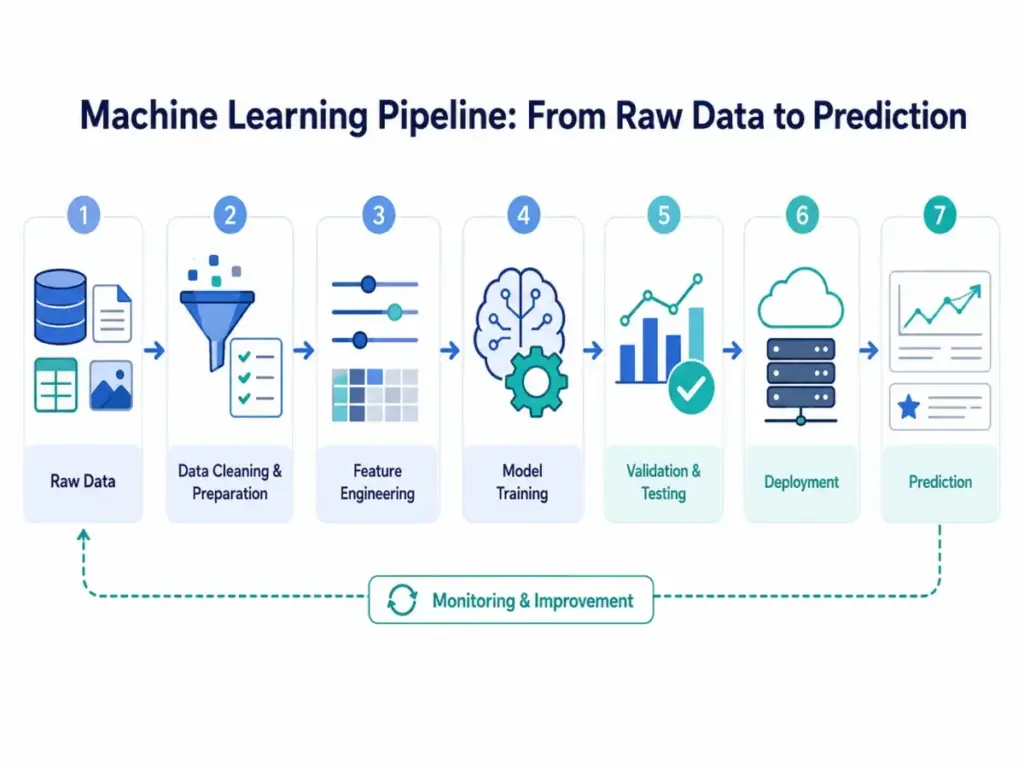
The pipeline looks like this at a high level: raw data goes in, features are selected, a model is trained, the model is tested on held-out data, and then the model is deployed to make predictions on new inputs. Monitoring follows deployment because real-world data changes over time.
How Does Machine Learning Work?
Machine learning follows a structured pipeline from raw data to deployed prediction. Each step introduces a specific failure risk that teams must understand before investing in ML.
Here is a practical breakdown of how machine learning models are trained and deployed:
| Step | What Happens | Business Example | Failure Risk |
|---|---|---|---|
| Data collection | Gather historical records | 12 months of support tickets | Too little data or missing labels |
| Feature selection | Choose input variables | Ticket length, customer tier, product area | Irrelevant features add noise |
| Training | Algorithm learns patterns | Model learns which tickets escalate | Overfitting to training data |
| Validation | Tune model settings | Compare model versions on held-out set | Data leakage from validation set |
| Testing | Estimate real performance | Test on data the model has never seen | Test set too small or not representative |
| Deployment | Model serves live predictions | Auto-route new tickets by priority | Latency, integration errors |
| Monitoring | Track accuracy over time | Weekly accuracy reports | Model drift as patterns change |
Data collection is where most ML projects succeed or fail. Without enough clean, labeled examples, no algorithm can learn useful patterns. “Garbage in, garbage out” is not a cliche here; it is an operational reality.
Feature selection determines what the model can see. If you build a churn prediction model but exclude billing data, the model cannot learn that late payments predict cancellation.
Training is the step most people associate with ML. The algorithm processes examples and adjusts internal parameters to minimize prediction error. But training alone means nothing without proper validation and testing.
Validation data tunes model choices. Test data estimates performance on unseen cases. Mixing these up creates false confidence. Data leakage, where information from the test set leaks into training, is one of the most common and damaging mistakes in applied ML.
Model drift means performance declines as real-world data changes. A lead scoring model trained on 2024 buyer behavior may perform poorly in 2026 if market conditions shift. MLOps, the practice of managing deployed models, exists specifically to catch and correct drift.
Machine Learning vs AI
Machine learning is one method for building AI, not a synonym for it. Understanding the distinction helps teams choose the right tool for their workflow.
The OECD defines an AI system as a machine-based system that infers from input how to generate outputs such as predictions, content, recommendations, or decisions. Machine learning is one way to build that inference capability. Rules-based automation is another. They solve different problems.
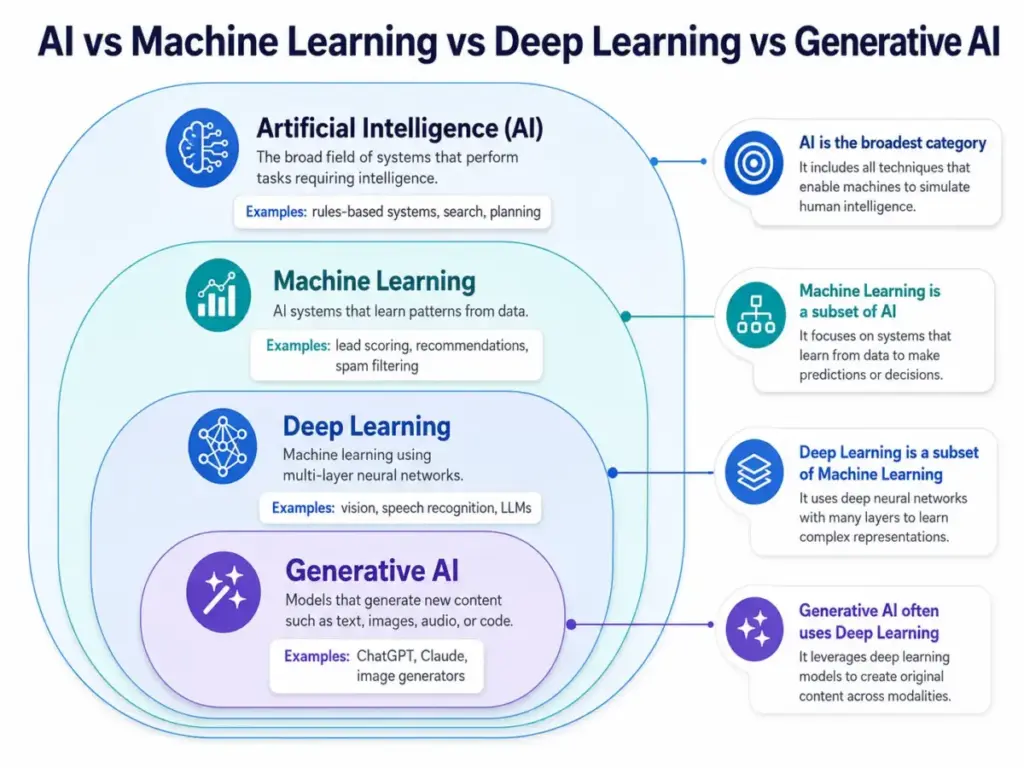
Here is how the key concepts relate:
- Artificial intelligence is the broadest category.
- Machine learning is a subset of AI that learns from data.
- Deep learning is a subset of ML using neural networks with many layers.
- Generative AI often uses deep learning models to produce new content.
- Large language models like ChatGPT and Claude use deep learning for language tasks.
- Natural language processing applies ML to language understanding and generation.
| Concept | What It Does | Simple Example | Best Fit |
|---|---|---|---|
| Rules-based automation | Follows explicit if/then instructions | If deal > $10K, assign to senior rep | Stable, well-defined processes |
| Analytics and BI | Summarizes historical data | Monthly churn rate dashboard | Reporting and trend identification |
| Machine learning | Learns patterns, makes predictions | Score each lead by conversion likelihood | Patterns too complex for manual rules |
| Deep learning | Learns from large unstructured data | Transcribe support calls to text | Image, audio, video, and language at scale |
| Generative AI | Produces new content from prompts | Draft a reply to a customer complaint | Content creation, summarization, Q&A |
| AI agents | Combine reasoning, tools, and memory | Research a prospect and draft outreach | Multi-step workflows with decisions |
The practical takeaway: most SaaS teams interact with ML through features inside their existing tools, not by building models from scratch. When a CRM scores a lead or a support platform routes a ticket, ML is often running behind the scenes.
Types of Machine Learning
Machine learning methods fall into four main categories, plus deep learning as a cross-cutting architecture. Each type fits different data conditions and business problems.
Choosing the right type depends on whether you have labeled data, how much data you have, and what outcome you need.
Supervised Learning
Supervised learning uses labeled examples to train a model. Each training record includes both the input (features) and the correct output (label). The model learns to map inputs to outputs.
SaaS example: A lead scoring model trained on historical deals. Each past lead is labeled “converted” or “did not convert.” The model learns which attributes (company size, engagement, industry) predict conversion.
Limitation: Requires a large set of accurately labeled data. If labels are noisy or biased, the model inherits those problems.
Use it when: You have a clear target outcome and enough historical examples with known results.
Unsupervised Learning
Unsupervised learning finds patterns in data without predefined labels. The algorithm groups, clusters, or reduces data based on structure it discovers on its own.
SaaS example: Customer segmentation. A clustering algorithm groups customers by behavior (usage frequency, feature adoption, support ticket volume) without being told which segments exist.
Limitation: Results require human interpretation. The algorithm finds groupings, but a person must decide what each group means and whether it is actionable.
Use it when: You want to discover hidden structure in your data and do not have labeled outcomes.
Semi-Supervised Learning
Semi-supervised learning combines a small set of labeled data with a larger set of unlabeled data. The model uses labeled examples to guide pattern discovery across the full dataset.
SaaS example: Classifying support tickets when only 500 out of 50,000 tickets have been manually categorized. The model uses the labeled subset to learn patterns, then applies those patterns to the unlabeled majority.
Limitation: Performance depends heavily on how representative the labeled subset is. A biased sample of labels propagates errors.
Use it when: Labeling is expensive or slow, but you have a large volume of unlabeled records.
Reinforcement Learning
Reinforcement learning trains an agent through trial and error. The agent takes actions in an environment and receives rewards or penalties based on outcomes. Over time, it learns a strategy that maximizes cumulative reward.
SaaS example: Dynamic pricing or ad bid optimization. The system adjusts bids in real time, receives feedback (click, conversion, or bounce), and refines its bidding strategy.
Limitation: Requires a well-defined reward function. A poorly designed reward can lead to unexpected or harmful behavior.
Use it when: The problem involves sequential decisions where feedback is available and the environment changes.
Deep Learning
Deep learning uses neural networks with many layers to learn from large volumes of unstructured data like images, text, audio, and video. It powers most modern generative AI systems.
SaaS example: AI-powered search that understands natural language queries. Deep learning models process the meaning behind a search query, not just keyword matches, to return relevant results.
Limitation: Requires large datasets and significant compute resources. Models are often difficult to interpret, which limits explainability.
Use it when: You have large-scale unstructured data and the problem requires understanding complex patterns in language, vision, or sequential data.
Machine Learning Examples
Machine learning appears in more business workflows than most teams realize. Here are ten concrete examples, mapped to real SaaS functions.
These are not hypothetical scenarios. Each represents a category of ML application that ships inside commercial software today.
Lead scoring in CRM. CRM software platforms use supervised learning to rank leads by conversion probability. The model trains on historical deals and assigns each new lead a score based on attributes like engagement level, company size, and industry match.
Churn prediction in SaaS. Subscription platforms train classification models on usage patterns, billing events, and support interactions. Accounts flagged as high-risk get targeted retention outreach before they cancel.
Support ticket routing. ML classifies incoming tickets by urgency, topic, and required expertise, then routes them to the right team. This replaces keyword-based rules that break when customers describe problems in unexpected ways.
Fraud detection. Financial and e-commerce platforms use anomaly detection to flag unusual transactions. The model learns normal behavior patterns and surfaces deviations for human review.
Product recommendations. E-commerce and media platforms use collaborative filtering and deep learning to suggest products or content based on past behavior and similar user profiles.
Demand forecasting. Regression models predict future demand based on historical sales, seasonality, promotions, and external factors. Supply chain and inventory teams use these forecasts to plan stock levels.
AI search and answer engines. Tools like Perplexity and internal knowledge bases use deep learning to understand query intent and return direct answers, not just link lists.
Email spam filtering. One of the oldest ML applications. Classification models trained on labeled spam and non-spam emails filter incoming messages with high accuracy.
Image classification. Computer vision models identify objects, defects, or categories in images. Manufacturing, medical imaging, and e-commerce product tagging all use this.
Predictive maintenance. Sensor data from equipment feeds regression and classification models that predict when a machine is likely to fail, allowing maintenance before breakdown.
Benefits of Machine Learning
Machine learning delivers specific advantages when applied to the right problems. Each benefit comes with a condition: ML works well only when data quality, volume, and monitoring support it.
Here is what ML can do that rules and manual analysis cannot match at scale.
Pattern detection at scale. ML processes thousands of variables across millions of records to find patterns that humans cannot spot manually. A churn model might discover that a specific combination of login frequency, feature usage, and billing cycle predicts cancellation.
Faster prediction cycles. Once trained, a model scores new inputs in milliseconds. A lead scoring model evaluates every new signup instantly, instead of waiting for a weekly manual review.
Better prioritization. ML replaces gut-feel ranking with data-driven scores. Sales teams work higher-probability leads. Support teams handle urgent tickets first. Marketing teams target segments with the highest predicted LTV.
Personalization. Recommendation engines tailor content, product suggestions, and outreach based on individual behavior. The model adapts as the user’s behavior changes.
Anomaly detection. ML identifies outliers in data that fixed thresholds would miss. Fraud detection, security monitoring, and quality control all benefit from adaptive anomaly scoring.
Adaptive systems. Unlike fixed rules, ML models can be retrained as conditions change. A demand forecasting model can incorporate new market signals without a full system rewrite.
Decision support, not decision replacement. Well-designed ML systems present predictions with confidence scores, letting humans make the final call. This matters most in high-stakes contexts like healthcare, finance, and legal operations.
Challenges and Limitations
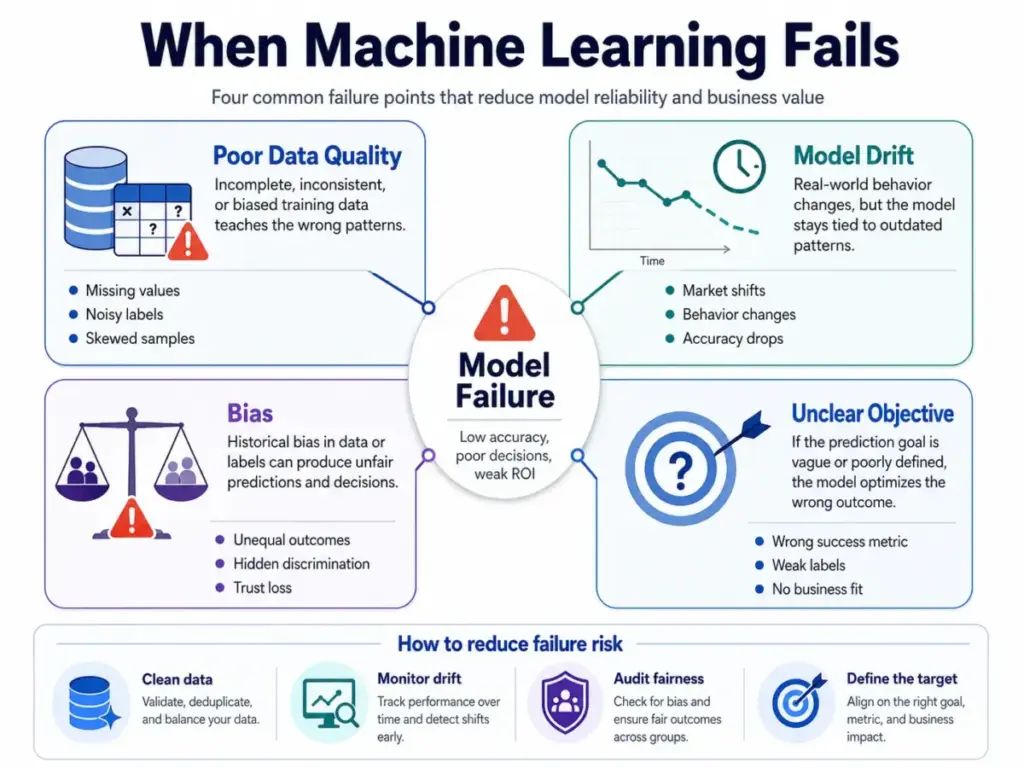
Machine learning is not a universal solution. Every ML project carries risks that increase when teams skip data preparation, monitoring, or governance steps.
Understanding these limitations prevents wasted budget and misplaced trust in model outputs.
Bad data creates bad models. If training data contains errors, duplicates, missing values, or biased samples, the model learns the wrong patterns. No algorithm compensates for fundamentally flawed data.
Bias can scale unfair decisions. ML models trained on historically biased data reproduce and amplify those biases. A hiring model trained on past decisions might discriminate against underrepresented groups. The NIST AI Risk Management Framework addresses this as a systemic governance challenge.
Model drift degrades performance. Real-world patterns change. A model trained on pre-pandemic customer behavior may fail in post-pandemic conditions. Without ongoing monitoring, accuracy declines silently.
Overfitting creates false confidence. A model that memorizes training data looks accurate during development but fails on new data. Proper validation and test procedures prevent this, but teams often rush past these steps.
Privacy and compliance matter. ML models trained on personal data must comply with GDPR, CCPA, and industry-specific regulations. Data retention policies, consent mechanisms, and right-to-deletion requests all affect what data a model can use.
Explainability limits trust. Complex models, especially deep learning, can be difficult to interpret. When a model rejects a loan application or flags a transaction, stakeholders need to understand why. Black-box predictions erode trust.
ML is often overkill for stable rules. If a workflow follows clear, fixed logic (e.g., “route all enterprise tickets to Tier 2”), a rules engine is cheaper, faster, and easier to maintain than an ML model.
When Not to Use Machine Learning
This is the section most ML articles skip. Knowing when not to use ML saves more money than knowing how to use it.
Use rules, workflow automation, or analytics before machine learning when the workflow is stable, the dataset is small, the cost of wrong predictions is high, or the team cannot monitor model performance.
The Rules vs ML Test
Ask these four questions before choosing ML:
- Does the pattern change over time? If no, use rules.
- Is there enough data? If fewer than a few thousand relevant examples, ML is unlikely to outperform simple heuristics.
- Is a wrong prediction recoverable? If a false positive causes irreversible harm (legal decisions, medical diagnoses), ML needs extreme caution and human oversight.
- Can someone monitor performance? If no one owns model accuracy after launch, performance will degrade without anyone noticing.
If you answer “no” to two or more questions, rules or analytics are likely the better choice.
| Situation | Better Choice Than ML | Why |
|---|---|---|
| Small dataset (under 1,000 records) | Rules or manual review | Not enough examples for ML to learn |
| Fixed, well-defined process | Rules engine or automation | Logic does not change; rules are cheaper |
| Legal or compliance decision | Human review with rules | Wrong predictions carry legal liability |
| Rare event with few examples | Statistical analysis or heuristics | ML needs volume to learn rare patterns |
| Low-stakes routing | Simple automation | ML overhead is not justified |
| No owner for monitoring | Rules or manual workflow | Unmonitored models degrade silently |
ML Readiness Score
Before investing in ML, score your readiness from 0 to 5:
- Clean data — Is the data accurate, complete, and consistently formatted?
- Clear target outcome — Can you define exactly what the model should predict?
- Enough examples — Do you have thousands of relevant historical records?
- Human fallback — Is there a process for when the model is wrong?
- Monitoring owner — Is someone responsible for tracking model accuracy after deployment?
Score 4 or 5: ML is worth exploring. Score 2 or 3: Fix gaps first. Score 0 or 1: Use rules or analytics.
Prediction, Generation, or Automation?
Many teams confuse what they actually need. Here is a quick decision guide:
- Need to route, assign, or trigger based on fixed conditions? Use workflow automation.
- Need to summarize historical data and spot trends? Use analytics and BI tools.
- Need to predict a future outcome (conversion, churn, demand)? Use predictive ML.
- Need to create content, summarize text, or answer questions? Use generative AI.
- Need to chain multiple steps with reasoning and tool use? Use AI agents.
How to Evaluate ML in SaaS Tools
Most SaaS buyers encounter machine learning as a feature inside existing software, not as a standalone platform. Evaluating these features requires asking specific questions.
Before trusting an AI-powered feature, understand what it is trained on, how it fails, and what controls you have.
Is the model trained on your data, vendor data, or both? Some tools use a general model. Others fine-tune on your account data. The answer affects accuracy and privacy.
Can you inspect why a prediction happened? Look for explainability features: confidence scores, contributing factors, or prediction breakdowns. If the tool says “high churn risk” but cannot explain why, trust is limited.
Can the feature be turned off? ML features that cannot be disabled create dependency. If accuracy drops, you need the option to revert to manual processes.
Does the vendor document data retention? Know how long your data is stored, whether it is used to train models for other customers, and whether you can request deletion.
Does performance improve or degrade over time? Ask whether the model is retrained on new data or frozen at launch. Frozen models drift.
What happens when predictions are wrong? Look for fallback workflows, human review queues, and error correction mechanisms.
Is pricing tied to usage, seats, credits, or add-ons? ML features sometimes sit behind premium tiers or usage-based pricing. Understand the cost structure before relying on the feature.
Best Tools for Machine Learning Concepts
Most SaaS buyers interact with ML through AI assistants, analytics platforms, CRM scoring, support routing, or cloud ML platforms. Building custom models is the exception, not the norm.
Here is how the major tool categories relate to machine learning concepts.
AI assistants and chatbots. Tools like ChatGPT, Claude, Gemini, and Perplexity use deep learning (specifically large language models) for language understanding and generation. They are the most visible ML-powered tools for non-technical teams. Read our ChatGPT review, Claude review, Gemini review, or Perplexity review for detailed evaluations. For a side-by-side comparison, see ChatGPT vs Claude. Our roundup of the best AI chatbots covers the full category.
Cloud ML platforms. Azure Machine Learning supports the full ML lifecycle: training, deployment, MLOps, monitoring, and retraining (docs). scikit-learn remains a standard open-source library for classical ML algorithms.
APIs for custom integration. OpenAI, Anthropic, and Google each offer APIs (OpenAI API, Claude API, Gemini API) that let developers embed ML capabilities into custom workflows. Perplexity also offers an API for search-augmented generation.
Prompt engineering is not machine learning itself, but it is how most non-technical users interact with ML-powered tools. Understanding prompt design helps teams get better results from AI assistants without building custom models.
| Tool or Category | How It Relates to ML | Best For | Watch-Out |
|---|---|---|---|
| ChatGPT, Claude, Gemini | Use deep learning LLMs for language tasks | Content drafting, Q&A, summarization | Hallucination risk on factual claims |
| Perplexity | ML-powered search with source citations | Research, fact-checking, competitive analysis | Citation accuracy varies by query |
| CRM AI features | Supervised learning for lead and deal scoring | Sales prioritization and pipeline forecasting | Accuracy depends on CRM data quality |
| Support AI routing | Classification models for ticket triage | Faster first response, reduced misrouting | Requires labeled ticket history to train |
| Azure Machine Learning | Full ML lifecycle platform | Teams building custom models with MLOps needs | Requires data engineering and ML expertise |
| scikit-learn | Open-source ML algorithms and evaluation tools | Prototyping, classical ML, education | No built-in deployment or monitoring |
Daniel Rivera’s Quick Take
Machine learning is not magic and not just “AI.” It is a prediction system built on data, objectives, and evaluation. The model is the least expensive part. The real cost is data readiness, monitoring, and recovering from bad decisions.
Most SaaS teams should first ask whether they need prediction, automation, content generation, or analytics. If the answer is prediction and the data supports it, ML is the right tool. If the answer is anything else, a simpler system will likely serve better and cost less.
Stable rules beat ML more often than vendors admit. Start with the problem, not the technology.
FAQ
What is machine learning in simple terms?
Machine learning is a way for software to learn patterns from examples instead of following rules written by a programmer. You give the system data with known outcomes, it finds patterns, and then it uses those patterns to make predictions on new data. The result is a reusable prediction system that improves as it processes more examples.
What are the 4 main types of machine learning?
The four main types are supervised learning (uses labeled data), unsupervised learning (finds patterns without labels), semi-supervised learning (combines labeled and unlabeled data), and reinforcement learning (learns through trial, error, and rewards). Deep learning, which uses multi-layer neural networks, cuts across these categories as an architecture rather than a separate type.
What is the difference between AI and machine learning?
AI is the broad field of building systems that can perform tasks requiring intelligence. Machine learning is one method within AI where systems learn from data rather than following explicit instructions. All ML is AI, but not all AI is ML. A rules-based chatbot is AI but not ML. A spam filter that learns from labeled emails is both.
What is the difference between machine learning and deep learning?
Deep learning is a subset of machine learning that uses neural networks with many layers to process large volumes of unstructured data like images, text, and audio. Classical ML algorithms work well on structured, tabular data with fewer features. Deep learning excels when data is complex and abundant but requires more compute power and is harder to interpret.
Is ChatGPT an example of machine learning?
Yes. ChatGPT is built on a large language model trained with deep learning techniques, which is a subset of machine learning. It was trained on large text datasets using supervised learning and reinforcement learning from human feedback. So ChatGPT is an example of both machine learning and deep learning, specifically applied to language generation.
What is a real example of machine learning?
Email spam filtering is one of the most common examples. The model trains on thousands of emails labeled as spam or not spam. It learns patterns (specific phrases, sender reputation, link density) and applies them to new incoming emails. Other everyday examples include product recommendations, voice assistants, and navigation apps predicting arrival times.
How does machine learning work step by step?
The core steps are: collect data, select features (input variables), split data into training, validation, and test sets, train the model on training data, validate and tune on the validation set, test on unseen data, deploy the model, and monitor accuracy over time. Each step has specific failure risks, from data quality issues in collection to model drift after deployment.
What is supervised learning?
Supervised learning trains a model using labeled data, where each example includes both the input and the correct answer. The model learns to map inputs to outputs. Classification (predicting categories like spam vs. not spam) and regression (predicting numbers like sales revenue) are the two main supervised learning tasks. It requires enough accurately labeled examples to work well.
What is unsupervised learning?
Unsupervised learning finds structure in data without labeled outcomes. Clustering groups similar records together. Dimensionality reduction simplifies data while preserving key patterns. A common business application is customer segmentation, where the algorithm identifies natural groupings based on behavior. The limitation is that results need human interpretation to become actionable.
What is machine learning used for in business?
Businesses use ML for lead scoring, churn prediction, fraud detection, recommendation engines, demand forecasting, support ticket routing, pricing optimization, and predictive maintenance. Most organizations consume ML through features embedded in SaaS tools rather than building custom models. CRM platforms, support software, and marketing tools all ship ML-powered features.
What are the limitations of machine learning?
Key limitations include dependence on data quality, risk of bias amplification, model drift over time, overfitting to training data, limited explainability in complex models, privacy and compliance constraints, and the cost of monitoring and maintenance. ML also requires a clear target outcome and sufficient data volume. Without these, simpler approaches work better.
Do small businesses need machine learning?
Most small businesses benefit more from rules-based automation and analytics than from custom ML. But many small teams already use ML indirectly through SaaS features like email spam filtering, CRM lead scoring, and AI chatbots. The question is not whether to build ML but whether the ML features inside existing tools add enough value to justify their cost tier.
Key Takeaways
- Machine learning is a method where software learns patterns from data and uses those patterns to make predictions, classifications, or recommendations.
- ML is a subset of artificial intelligence. Deep learning is a subset of ML. Generative AI often uses deep learning models.
- ML works best when patterns are too complex or too fast-changing for manual rules, and when enough quality data exists to train on.
- ML fails when data is poor, objectives are unclear, monitoring is absent, or governance is weak.
- Most SaaS buyers use ML through built-in product features, not by training custom models.
- Before choosing ML, determine whether you actually need prediction, automation, content generation, or analytics.
- Stable rules beat ML more often than vendors admit. Start with the problem, not the technology.





