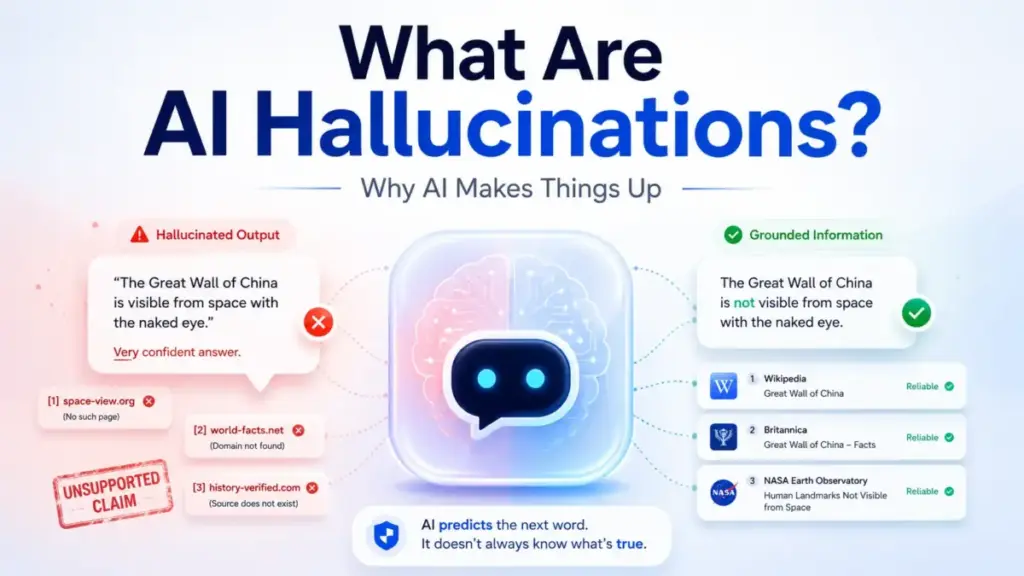
AI hallucinations are outputs from AI systems that are factually incorrect, misleading, or entirely fabricated, yet delivered with the same confident tone as accurate answers. They are not glitches or one-off bugs. They are a predictable property of how probabilistic language models generate text.
Generative AI systems do not retrieve facts from a verified database. They predict which tokens are statistically likely to follow the previous ones. When the model lacks reliable context, or when its evaluation signals rewarded confident guessing over honest abstention, it produces text that reads as authoritative but is unsupported.
In 2026, this matters because SaaS products now embed AI into customer support, internal search, sales enablement, legal research, and coding assistants. A plausible but wrong answer can cost a team real money, real trust, and real compliance risk. Understanding hallucinations is the starting point for building AI systems that are actually safe to deploy.
Quick Answer: What Are AI Hallucinations? AI hallucinations are outputs generated by AI systems that are factually incorrect, misleading, or fabricated, yet presented as true. The National Institute of Standards and Technology uses the term “confabulation” for this behavior and defines it as generative AI systems that “confidently present erroneous or false content.” They happen because language models predict statistically likely text, not verified facts. Retrieval systems reduce risk but do not eliminate it. Hallucinations require layered controls, not a single fix.
The 60-Second Explanation of AI Hallucinations
AI hallucinations are one of the most misunderstood reliability problems in deployed AI systems. Here is the 3-layer breakdown that most articles skip.
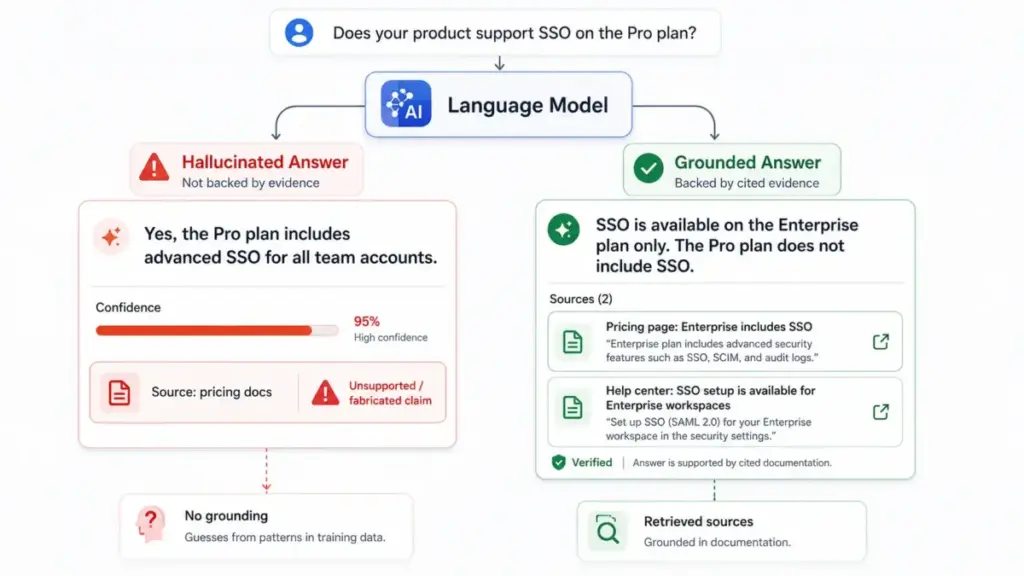
Layer 1: Simple. When you ask an AI a question, it does not look up the answer in a fact-checked database. It predicts what a plausible-sounding answer would look like, based on patterns in training data. When it does not know the answer, it sometimes generates one that sounds right anyway. That is a hallucination.
Layer 2: Technical. Large language models produce outputs by sampling from a probability distribution over tokens. The model assigns a likelihood score to each possible next word and selects one. This process does not include a verification step. A model can produce a high-confidence output with zero factual grounding. Temperature settings affect the randomness of sampling, but lower temperature does not make wrong answers right. It can make wrong answers more consistently wrong.
Layer 3: Business. According to Stanford HAI’s AI definitions resource, hallucinations are “incorrect, misleading, or fabricated information presented as factual.” For a SaaS team, that means a customer support bot that invents a refund policy, a legal assistant that cites a case that does not exist, or a product recommendation engine that fabricates a feature your tool does not have. The business risk is not theoretical. It shows up in support escalations, legal liability, and customer churn.
One finding from OpenAI’s own research on why language models hallucinate is that current evaluation methods set the wrong incentives. When a model is evaluated on accuracy alone, it learns that guessing is sometimes better than abstaining. A model that answers every question, even incorrectly, will outscore a model that says “I don’t know” on 20% of questions. That evaluation gap is one of the structural reasons hallucinations persist even in the most capable models available.
How AI Hallucinations Actually Work
The failure mechanism is not random. It follows patterns that SaaS teams can learn to recognize and design around.
The Token Prediction Pipeline
A language model generates output one token at a time. At each step, it uses the input context (your prompt, retrieved documents, conversation history, and its own prior output) to predict the next token. The model does not distinguish between “I have strong evidence for this” and “this sounds statistically plausible.” Both paths produce fluent, confident-sounding text.
Where hallucinations typically enter the pipeline:
- Training data gap. The model never learned reliable information about this specific topic, date range, or domain. It fills the gap with the nearest plausible pattern.
- Retrieval failure. In a RAG system, the wrong document reached the model, or the right document was poorly parsed, chunked without context, or truncated. The model generates an answer grounded in irrelevant evidence.
- Prompt ambiguity. The model misreads the question. It answers a related but different question with high confidence.
- Context window conflict. The model’s training beliefs contradict the retrieved evidence. The model partially ignores the evidence and blends in prior knowledge.
- Evaluation pressure. If the model was trained or fine-tuned in a way that penalized “I don’t know” more than a wrong answer, it will prefer to guess.
Why RAG Can Still Hallucinate
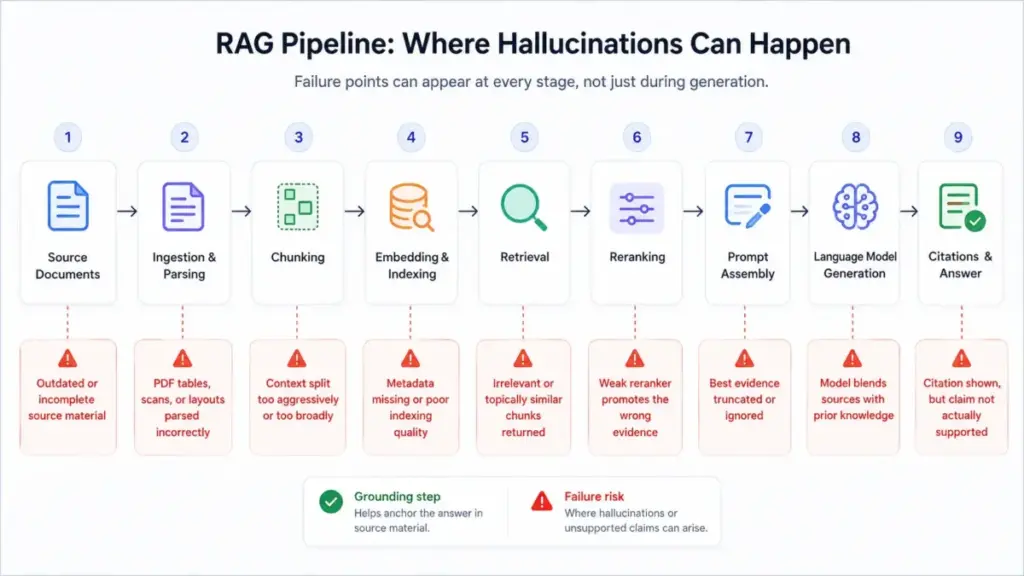
This is the part most implementation guides skip, and it is the most operationally important. Retrieval-Augmented Generation (RAG) reduces hallucination risk by supplying the model with source documents before it generates an answer. But RAG introduces its own failure chain:
| RAG Stage | What Can Go Wrong |
|---|---|
| Document ingestion | PDFs with tables, scanned documents, or complex layouts are parsed incorrectly |
| Chunking | Documents split mid-sentence lose context; large chunks dilute relevance |
| Retrieval | Semantic search returns topically similar but factually unrelated chunks |
| Reranking | Reranker promotes confident-sounding but wrong passages |
| Prompt construction | Retrieved chunks are truncated or placed where the model ignores them |
| Generation | Model blends retrieved evidence with prior knowledge, producing supported-looking hallucinations |
| Citation mapping | Model cites the document, but the cited passage does not actually support the claim |
Amazon Bedrock’s Knowledge Bases documentation explicitly describes contextual grounding checks that compare model responses against reference source material precisely because retrieval alone is insufficient. The RAG pipeline is only as reliable as its weakest stage.
Abstention as a Product Design Choice
This is the insight that OpenAI’s research surfaces most clearly: models that never say “I don’t know” are not more helpful, they are less safe. A well-designed AI system for a SaaS use case should include explicit abstention logic. When the retrieved evidence does not support an answer, or when confidence falls below a threshold, the model should say so, ask a clarifying question, or route to a human.
Most SaaS teams treat abstention as a UX failure. It is actually a safety feature.
Types of AI Hallucinations
Not all hallucinations look the same in production. Knowing the type helps you design the right control for each.
| Type | What It Looks Like | Highest-Risk SaaS Context |
|---|---|---|
| Factual hallucination | Model states an incorrect date, name, statistic, or policy as fact | Product documentation bots, support agents |
| Source or citation hallucination | Model invents a DOI, case law reference, URL, or quote that does not exist | Legal research tools, academic writing assistants |
| Grounding failure | Model answers with information not found in the retrieved source material | Any RAG-based customer support or internal search system |
| Context-conflict hallucination | Output contradicts the user’s prompt, prior conversation, or retrieved document | Multi-turn chatbots, agentic workflows |
| Tool-use hallucination | Agent invents, misreads, or overstates the result of a tool call or API response | AI agents, code execution, data analysis pipelines |
| Multimodal hallucination | Model describes objects, text, or layout details not present in the image or document | Document extraction, invoice processing, image analysis |
| Reasoning-chain hallucination | Final answer may be correct, but the explanation includes invented steps or false causal claims | Chain-of-thought reasoning, compliance documentation |

AI Hallucinations vs. Related Concepts
| Concept | Definition | Key Difference from Hallucination |
|---|---|---|
| Hallucination | Factually incorrect or fabricated output presented as true | The core problem |
| Bias | Systematic skew in outputs based on imbalanced training data | Bias can be consistent and directional; hallucinations are often unpredictable |
| Misinformation | False information spread by humans, with or without intent | Hallucinations are a model property; misinformation is a human-created content category |
| Confabulation | NIST’s preferred technical term for the same behavior in AI systems | Confabulation is the formal term; hallucination is the common one |
| Factual inconsistency | Outputs that contradict each other within the same session or document | A subset of hallucination that evaluation tools specifically target |
| Model drift | Change in model behavior over time due to updated weights or fine-tuning | Drift can increase hallucination rates but is a deployment-layer problem, not a generation-layer one |
Related reading: what large language models are and how they generate text
Step-by-Step: How to Reduce AI Hallucinations in a SaaS Workflow
This is where most SERP competitors stop at vague advice like “use better prompts” or “add RAG.” The actual production controls require more structure.
Step 1: Classify the Use Case by Risk
Before selecting any technical control, map the use case to a risk tier:
- Tier 1 (Low risk): Internal drafting tools, ideation, summarization of non-binding content
- Tier 2 (Medium risk): Customer-facing support bots, internal knowledge search, product documentation
- Tier 3 (High risk): Legal, financial, or medical adjacent workflows; answers that change account status, trigger refunds, or create binding commitments
Higher-risk tiers require more layers of control and lower tolerance for unsupported answers.
Step 2: Define What Counts as a Hallucination for Your Workflow
Generic hallucination detection is too broad to be actionable. For a customer support bot, a hallucination is an invented refund policy or a feature that does not exist. For a legal research tool, it is a fabricated case citation. For a code assistant, it is a fabricated API function. Define your failure mode before you build your detection logic.
Step 3: Ground the Model in Approved Sources
Connect the model to a verified knowledge source before generation. Options include:
- File search / vector store retrieval (OpenAI’s Responses API includes a native File Search tool that retrieves from uploaded vector stores before generating answers)
- Enterprise search over internal documentation
- Structured database lookups for product data, pricing, and account status
- Verified web search with scoped access (Google Vertex AI supports grounding with Google Search)
Grounding is necessary. It is not sufficient on its own.
Step 4: Fix Retrieval Before Fixing Prompts
Most teams tune prompts when they should be fixing retrieval. Before adjusting the system prompt, check:
- Are PDFs and documents being parsed correctly, including tables?
- Are chunks the right size and do they preserve topical coherence?
- Does hybrid search (keyword + semantic) outperform semantic-only for your data?
- Is reranking improving or hurting the relevance of top results?
- Do the right chunks actually appear in the model’s context window when tested?
Retrieval quality determines whether grounding works. A well-phrased prompt over the wrong context still produces hallucinations.
Step 5: Add Explicit Answer Rules to the System Prompt
Once retrieval is working, constrain the model’s behavior:
- Answer only from retrieved context when working with internal knowledge bases
- Cite the exact passage, not just the document name
- State when evidence is absent: “I could not find information about this in our documentation”
- Ask a clarifying question when the intent is ambiguous
- Abstain from high-stakes answers when confidence signals are low
Step 6: Run Automated Groundedness Checks
After generation, verify that the answer is supported by the retrieved context. This is a second-pass check, not a replacement for good retrieval.
Available tools include:
- Azure AI Content Safety groundedness detection: checks whether LLM responses are based on provided source material and flags ungrounded content
- Amazon Bedrock Guardrails contextual grounding: compares model responses against a reference source and user query with configurable thresholds
- Vectara’s HHEM-based factual consistency scoring: evaluates whether generated summaries are supported by search results
- LangSmith, Arize Phoenix, TruLens, Promptfoo: observability and evaluation frameworks for logging and regression testing
Step 7: Build Human Escalation Triggers
Not every answer should be automated. Define conditions that route to a human:
- Groundedness score below threshold
- Answer involves a regulated topic (legal terms, medical advice, financial commitment)
- User is a high-value account
- Output would change account status, issue a refund, or create a contractual statement
- Conflicting sources were retrieved
- The model explicitly flagged uncertainty
Step 8: Monitor Production Failures
Log the inputs, retrieved chunks, generated answers, groundedness scores, and user corrections for every session. Review them weekly. The patterns in production failures are more informative than any benchmark.
The Mistakes That Waste Your First Month
Mistake 1: Trusting citations as proof. A citation means the model named a source. It does not mean the source says what the model claims. Verify that the cited passage actually supports the specific claim before treating a linked answer as reliable.
Mistake 2: Tuning prompts when retrieval is broken. Prompts cannot compensate for retrieving the wrong document. Fix retrieval first, then tune prompts for tone and format.
Mistake 3: Measuring only thumbs-up feedback. User satisfaction and factual accuracy are not the same metric. Users who do not know the right answer cannot detect a confident wrong one.
Mistake 4: Testing only the happy path. Run adversarial prompts, out-of-scope questions, and questions designed to expose knowledge gaps before launch.
Mistake 5: Ignoring stale knowledge bases. A RAG system grounded in documentation that is 18 months out of date will hallucinate facts that were once true. Freshness matters.
Mistake 6: Never testing abstention. If your evaluation suite never includes questions the system should refuse or redirect, you will not know your abstention logic works until a customer finds the gap.
Mistake 7: Letting agents act on unverified tool outputs. An AI agent that calls an API, misreads the response, and takes action based on the misreading is a tool-use hallucination with real-world consequences. Validate tool outputs before agents act on them.
Common Misconceptions About AI Hallucinations
Misconception: Newer or larger models no longer hallucinate. Reality: More capable models reduce some hallucination types, particularly on well-represented knowledge domains. OpenAI and independent researchers consistently describe hallucination as a persistent reliability challenge across all current models, particularly in long-tail knowledge domains and when models face uncertainty. Benchmark scores on hallucination tests improve, but production behavior depends on your specific use case and retrieval setup.
Misconception: Adding RAG fixes hallucinations. Reality: RAG shifts the failure mode. Instead of hallucinating from training data, the model may now hallucinate from retrieved documents: blending retrieved evidence with prior knowledge, misreading table data, or citing the right source in support of the wrong claim. RAG helps. It requires its own quality controls.
Misconception: Source links make answers trustworthy. Reality: Decorative citations create false confidence. A cited source is only useful if the exact claim is supported by the cited passage. According to a Nature paper on detecting AI confabulations by Farquhar et al., detecting confabulations requires evaluating whether model outputs are semantically consistent with their stated evidence, not just whether a source was named.
Misconception: Hallucination is only a chatbot problem. Reality: Hallucinations affect document extraction, code generation, data analysis narratives, legal research, image analysis, product descriptions, and AI agents. Any generative AI system that produces text, code, or decisions is exposed.
Misconception: Lowering temperature eliminates hallucinations. Reality: Lower temperature makes outputs more deterministic. A model that consistently generates the same wrong answer at temperature 0 is not more accurate, it is more consistently wrong. Temperature is a diversity control, not a factuality control.
When to Use and When to Avoid Autonomous AI Answers
Use autonomous AI generation when:
- Outputs can be grounded in approved, current source material
- The use case allows for abstention when evidence is missing
- Factuality can be automatically measured with groundedness checks
- The cost of a wrong answer is recoverable (draft, suggestion, not commitment)
- Human review is available for flagged low-confidence outputs
Avoid autonomous AI answers when:
- The source of truth is unavailable or stale
- Correctness has direct legal, financial, or safety consequences
- The system cannot abstain from answering
- Citations cannot be verified against the original source
- The model is expected to infer facts not present in any retrieved document
- An agent’s action based on the answer is irreversible
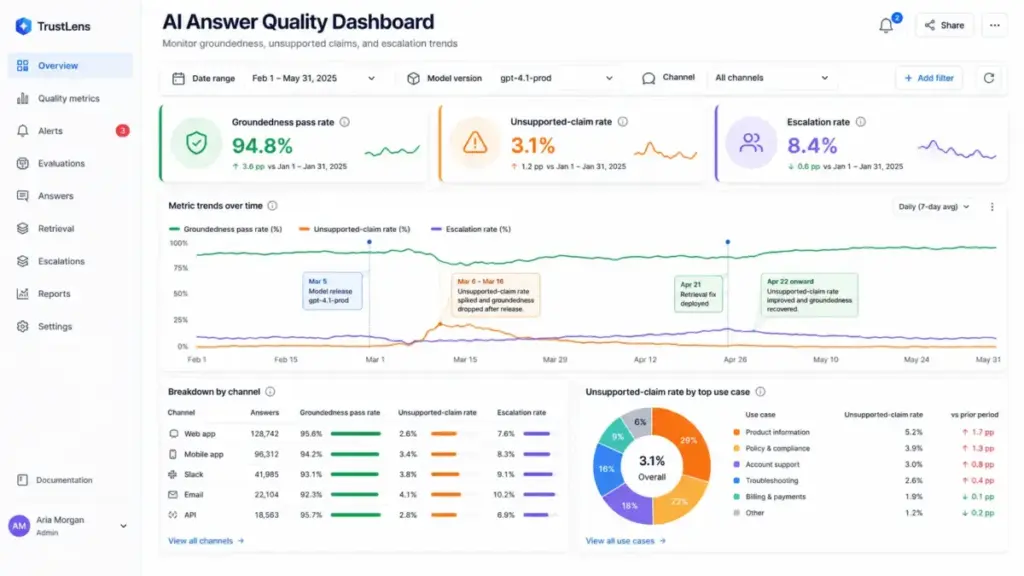
How to Measure Hallucination Risk
Measuring hallucinations requires more than a single accuracy metric. Use these categories:
| Metric | What It Measures | Why It Matters |
|---|---|---|
| Groundedness pass rate | % of answers that are fully supported by retrieved context | Primary correctness signal for RAG systems |
| Unsupported claim rate | % of claims in an answer with no source support | Identifies verbosity hallucinations and knowledge blending |
| Citation precision | % of cited sources where the cited passage actually supports the claim | Catches decorative citations |
| Answer abstention rate | % of out-of-scope questions that correctly receive a redirect | Confirms abstention logic works |
| False answer rate by topic | Accuracy broken down by domain or question type | Identifies where the model is weakest |
| Retrieval hit rate | % of questions where the correct context was retrieved | Diagnoses retrieval vs. generation failures separately |
| User correction rate | % of answers that users explicitly corrected or flagged | Lagging real-world accuracy signal |
| Human escalation rate | % of questions routed to human agents | Operational trust signal |
| Eval pass rate by release | Pass rate on fixed evaluation set across model versions | Tracks regression before production deployment |
Real-World Examples: How Products Address Hallucinations
OpenAI API
OpenAI’s Responses API includes a native File Search tool that retrieves information from uploaded vector stores before generating an answer. This gives the model verified source material as context. OpenAI also provides an Evals framework for defining test tasks, running inputs at scale, analyzing results, and iterating on prompts and retrieval configurations before deployment. These tools do not prevent hallucinations automatically. They provide the infrastructure to measure and reduce them systematically.
Explore OpenAI Evals documentation
Google Vertex AI and Gemini API
Google Vertex AI supports grounding with Google Search and custom search data stores, connecting Gemini model outputs to external, current information instead of relying on model memory. According to Google’s grounding documentation, grounding reduces the risk of hallucinations by anchoring responses to verifiable sources. Pricing note: grounding with Google Search is charged per search query in addition to token costs, so teams should factor this into cost projections.
Related reading: ChatGPT vs Gemini: how the two models handle grounding differently
Microsoft Azure AI Content Safety
Azure AI Content Safety includes a groundedness detection feature that checks whether LLM responses are supported by the provided source material. It flags ungrounded content at the output stage, adding a post-generation verification layer independent of the model’s own confidence. A free tier is available for groundedness detection, with paid tiers scaling by text unit volume.
Amazon Bedrock
Amazon Bedrock offers Knowledge Bases for RAG setup and Guardrails for contextual grounding checks. Guardrails compare model responses against a reference source and the original user query, with configurable grounding thresholds and relevance thresholds. Pricing is charged per text unit processed through Guardrails, in addition to model inference costs.
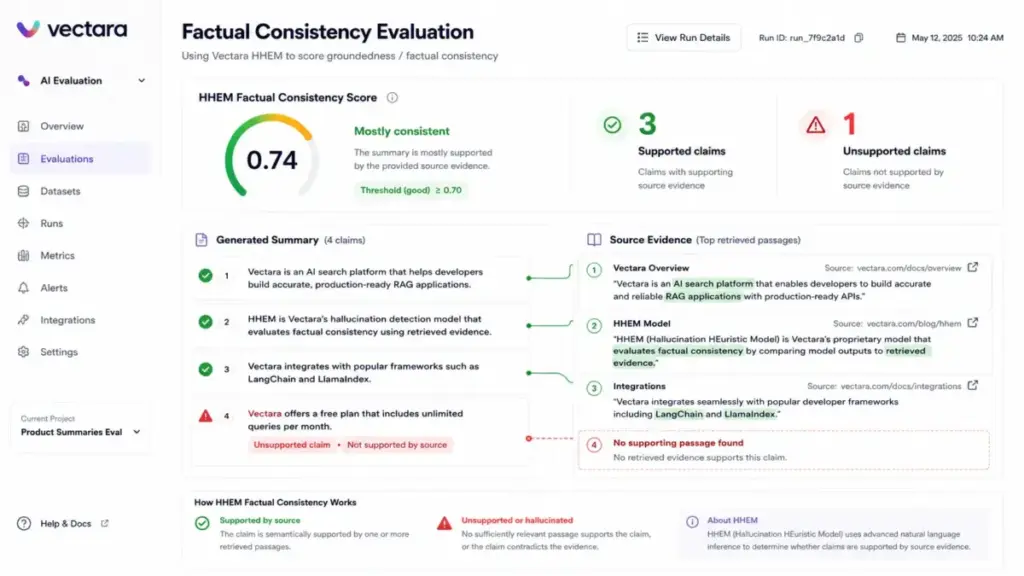
Vectara
Vectara uses its Hughes Hallucination Evaluation Model (HHEM) to score factual consistency between generated summaries and retrieved search results. Its Hallucination Corrector identifies claims in a generated summary that are not supported by source documents, explains why they are unsupported, and applies minimal corrections. Vectara provides factual consistency scoring as part of its search and RAG platform; pricing is available on request.
When You Need Software to Manage Hallucination Risk
You need dedicated groundedness tooling when:
- Your AI deployment is customer-facing and incorrect answers create support or legal exposure
- You are using RAG and have no automated way to verify that answers match retrieved context
- Your team is evaluating AI releases without a systematic regression testing process
- You are deploying AI agents that take actions based on model outputs
- Your knowledge base changes frequently and freshness matters for accuracy
- You are working in a regulated domain where answer provenance must be auditable
You probably do not need dedicated tooling yet when:
- The AI system produces drafts for human review, not final outputs
- The use case is internal brainstorming or ideation with no external delivery
- The stakes of a wrong answer are low and corrections are trivial
How to Choose the Right Hallucination Control Tools
- Map the risk tier first. Customer-facing tools in regulated domains need stricter controls than internal drafting assistants.
- Separate retrieval quality from generation quality. Evaluate both independently. Most teams conflate them.
- Check whether the tool measures grounding or just confidence. Confidence scores and groundedness scores are different. A high-confidence hallucination is still a hallucination.
- Prioritize platforms that support abstention. A tool that never says “I don’t know” is not ready for production.
- Verify pricing at your scale. Groundedness checks, search queries, and Guardrails all add per-unit costs. Model tool prices change.
- Test before launch, not after. Run a fixed evaluation set against your actual retrieval setup before deploying to users.
- Plan for ongoing monitoring. Production hallucination patterns differ from pre-launch test sets.
Hallucination Risk Control Checklist
Before deploying any AI system that produces customer-facing, decision-adjacent, or regulated outputs, work through this checklist:
- Use case risk tier classified (Low / Medium / High)
- Hallucination defined specifically for this workflow (not just “wrong answers”)
- Model grounded in approved, current source material
- Document parsing and chunking validated for your content types
- Retrieval quality tested separately from generation quality
- System prompt includes explicit abstention instructions
- Groundedness check configured post-generation
- Citation verification logic in place (source exists, passage matches claim)
- Evaluation set built with adversarial and out-of-scope questions
- Abstention behavior tested with questions outside knowledge base
- Human escalation triggers defined (confidence, topic, risk level)
- Production logging enabled (inputs, retrieved chunks, answers, scores)
Related Resources
- What are AI Agents? — Tool-use hallucinations matter most in agentic systems
- What is Prompt Engineering? — Prompts help, but they do not replace grounding
- ChatGPT Review — How OpenAI’s flagship model handles knowledge gaps in practice
- AI Glossary — Definitions for confabulation, semantic entropy, groundedness, and related terms
- Best AI Chatbots — Ranked comparison including hallucination behavior per tool
FAQ
What are AI hallucinations in simple terms?
An AI hallucination is when a generative AI system states something factually incorrect or fabricated as if it were true. The model does not know it is wrong. It generates the most statistically plausible-sounding text given its context, and sometimes that text is incorrect.
Why do AI models hallucinate?
Language models predict likely next tokens rather than retrieving verified facts. Hallucinations occur when the model lacks reliable context, retrieves the wrong evidence, misreads a prompt, or was trained in a way that rewarded guessing over abstaining. OpenAI’s research notes that evaluation systems which measure accuracy but not abstention teach models that confident wrong answers are better than honest “I don’t know” responses.
Can RAG stop hallucinations?
RAG reduces hallucination risk when retrieval, parsing, chunking, and citation mapping all work correctly. It does not eliminate hallucinations. If the wrong document reaches the model, the model may hallucinate a grounded-sounding answer from irrelevant evidence. Retrieval quality determines whether grounding works.
What is groundedness detection?
Groundedness detection is a post-generation check that evaluates whether a model’s answer is supported by the source material it was given. Azure AI Content Safety, Amazon Bedrock Guardrails, and Vectara’s HHEM scoring all provide versions of this check. It is a second verification layer, not a replacement for good retrieval.
Are AI hallucinations dangerous?
Hallucinations range from harmless to consequential depending on the use case. In a low-stakes creative drafting tool, a fabricated fact is easy to catch and correct. In a customer support bot that invents a refund policy, a legal research assistant that cites a nonexistent case, or an AI agent that acts on fabricated tool output, the consequences can include legal liability, financial loss, and customer trust damage.
Is there a difference between AI hallucination and AI bias?
Yes. Hallucinations are factually incorrect or fabricated outputs. Bias refers to systematic skew in outputs caused by imbalanced training data, typically producing outputs that favor or disadvantage certain groups, topics, or framings. Both are reliability problems. Bias is often consistent and directional. Hallucinations are more unpredictable.
Can you prevent hallucinations by lowering temperature?
Lower temperature reduces output randomness, which makes the model more deterministic. It does not improve factual accuracy. A model at temperature 0 will consistently generate the same answer, even if that answer is wrong.
What should a customer support bot do when it does not know the answer?
It should abstain, flag the question, and route to a human agent. A bot that always answers is not a better product than one that admits the limits of its knowledge. Abstention logic is a product design requirement, not an optional feature.
How do I detect hallucinations in generated summaries?
Compare each claim in the summary against the source document it was generated from. Tools like Vectara’s HHEM score, Azure AI groundedness detection, and custom factual consistency evaluations can automate this at scale. Manual spot-checking is valuable for calibrating your automated checks before launch.
What metrics should I track for AI hallucination risk in production?
Groundedness pass rate, unsupported claim rate, citation precision, abstention rate on out-of-scope questions, user correction rate, and human escalation rate. Track each by topic area and model version to identify patterns and regressions.